DataCrate - a progress report on packaging research data for distribution via your repository
2019-07-01

This is a talk that I delivered at Open Repositories 2019 in Hamburg Germany, reporting on developments in the DataCrate specification for research data description and packaging. The big news is that DataCrate is now part of a broader international effort known as RO-Crate. I spent several hours at the conference working with co-conspirators Stian Soiland-Reyes and Eoghan Ó Carragáin on the first draft of the new spec which we hope to unveil at eResearch Australasia 2019.
Eoghan, Stian and I ran a workshop at OR2019 for repository people to talk about the state of the art in Research Data Packaging, and collect use cases - we got lots of useful input from the workshop and the broader conference and had a chance to chat with people working on related standards such as the Oxford Common File Layout (OCFL) and Sword 3 - Neil Jeffries, Andrew Woods, Simeon Warner and my old mate Richard Jones amongst others.
I also presented work that Mike Lynch, Moises Sacal and I have been doing on OCFL.
My travel was funded by the University of Technology Sydney.
Peter Sefton
University of Technology Sydney, Australia
DataCrate is a specification for packaging research data for dissemination and reuse which has been presented at OR before as it developed to its current v1.0 status. This is an update on progress with the specification and tooling. The goals are of the specification are, (a) to maximise the utility of the data for researchers (including the original researchers' 'future selves') - given that a researcher has found a DataCrate package they should be able to tell what it is, how the data may be used and what all the files contain, (b) to enable discovery of the data by exposing metadata as widely as possible to both humans and machines and (c) to enable automated ingest into repositories or catalogues. DataCrate can express detailed information about which people, instruments and software were involved in capturing or creating data, where they did it and why, as well as how to cite a dataset. DataCrate draws on other standards (BagIt, JSON-LD, Schema.org) and is designed to be easy to implement.

When I proposed this update there had been some work going on to merge DataCrate with another standard - Research Object - but we didn’t know what form that would take. This presentation will now let the love-stuck cat out of the bag. I’m going to tell you a love story about two standards.
The story is about DataCrate - which is a Specification for describing and distributing data (any data).

And Research Object which is also about data packaging but with more emphasis on having a major impact on scholarly communications and practice, including distributing research data with code and workflows in the interests of making it more reproducible.

There’s going to be a marriage of these two standards.

But before we talk about the upcoming marriage of two specifications, let’s go back over what we’re trying to achieve. I will use examples from DataCrate but the same principles apply with Research Object.

Self-documenting: Describe the stuff in a programmer friendly way (eg FD, DataCrate), with a view to making it interoperable (eg DataCrate, RO), try to ensure Reusability (RO) - add human readable HTML (DataCrate, DataSpice)
Self-contained: Bundle stuff (eg Zip, TAR, .dmg, RAR).
Safe: Make sure the stuff is what it’s supposed to be using checksums (eg BagIt, FD) & Preservation / archival practice
Serialization Syntax: XML (Legacy systems), JSON (FD) Linked Data (RDF, JSON-LD eg RO, DataCrate)
Schemas - which one(s) to use?")
Here’s a slide from the workshop we ran at the OR conference, setting out some of the functional requirements for a distribution format.

Here’s a screenshot from a sample DataCrate. It shows the basic metadata for the dataset. This example is online, but the same view is available if you download it as a zip file.

If you do download the zip then you’ll see these files - the payload data is/are in the /data directory and the other files are all metadata and fixity checking information. A human can open CATALOG.html and then click around a little website that describes the data, including information down to the file level and about the contents of files.

There’s also machine readable data in JSON-LD format.

The JSON-LD is designed to be easily consumed by programs that can do things with the data - and is compatible ith Google’s DataSet search.

The two views (human and machine) of the data are equivalent - in fact the HTML version is generated from the JSON-LD version using a tool called CalcyteJS.

Here’s a screenshot of an HTML page about one of the files in the sample dataset - including detailed EXIF technical metdata which from INSIDE the file.

And here’s an automatically generated diagram extracted from the sample DataCrate showing how two images were created. The first result was an image file taken by me (as an agent) using two instruments (my camera and lens), of a place (the object: Catalina park in Katoomba). A sepia toned version was the result of a CreateAction, with the instrument this time being the ImageMagick software. The DataCrate also contains information about that CreateAction such as the command used to do the conversion and the version of the software-as-instrument.
convert -sepia-tone 80% test_data/sample/pics/2017-06-11\ 12.56.14.jpg test_data/sample/pics/sepia_fence.jpg

Because DataCrate is based on JSON-LD, and linked data principles, each term used can have a link to its definition, eg: https://schema.org/CreateAction so DataCrates are self-documenting.
ing is limited:
JSON-LD → 🙅
⛓💾 → 👶</p>
<p>")
BUT. tools for humans to generate linked-data are under-developed.
JSON-LD tooling is limited to high-level transformations and there are no easily available libraries for Research Software Engineers to do simple stuff like traversing graphs or looking up context keys.

Linked data is still too much like rocket science because of all the architecture astronauts:
These are the people I call Architecture Astronauts. It’s very hard to get them to write code or design programs, because they won’t stop thinking about Architecture. They’re astronauts because they are above the oxygen level, I don’t know how they’re breathing. They tend to work for really big companies that can afford to have lots of unproductive people with really advanced degrees that don’t contribute to the bottom line.
Also, as with many technologies, RDF can be a bit of a religious matter.

Speaking of relgion, back to the wedding of the decade ...
The new entity is called RO-Crate.
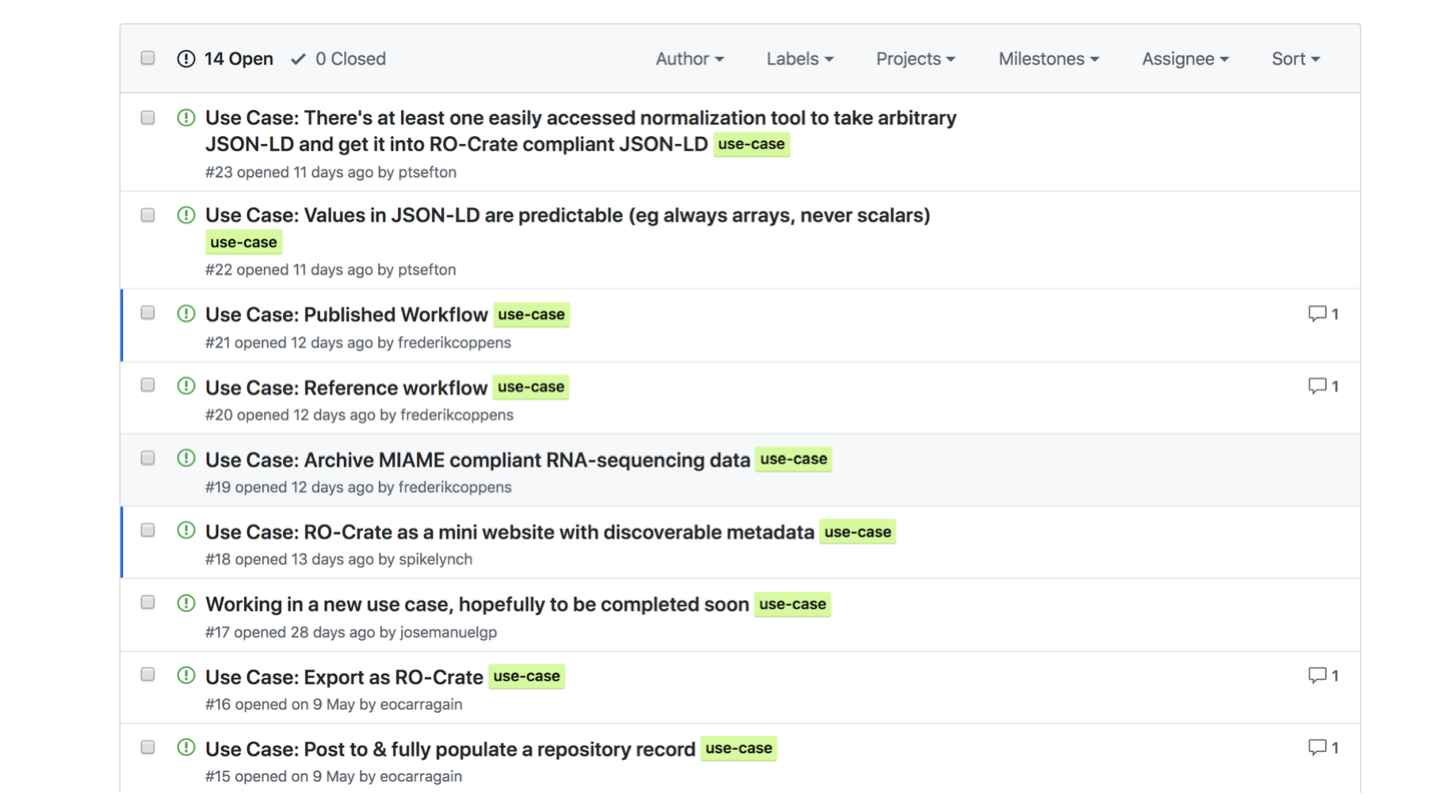
We are collecting use-cases in the github repo. We collected several at our OR2019 workshop, and the the repository is still open for business.

Members of the OR-Crate project (anyone can join by following the directions at the repo) are reviewing the spec - which is based on a set of examples - and we expect to have a simplified, clearer specification draft by the end of July, and to launch an Alpha version in October at eResearch Australasia (subject to getting presentation accepted :).

How does RO-Crate work with BagIt, OCFL, Zip et al
How can I re-run this analysis? Via a workflow?
How can I do stuff with this dataset?</p>
<p>")
We’re working on merging the DataCrate simple-to-implement approach with the bigger vision of Research Object.

Join us!