Open Repositories 2018 Presentation: ReDBox 2.0 / Provisioner
2018-07-06
This is a presentation that Gavin Kennedy and I gave at Open Repositories 2018 in Bozeman Montana.
I am posting this on the UTS eResearch website and on my own site.

Notes - Slide 1
The first part of this presentation was narrated by Gavin.

Managed and supported by QCIF
Fully customisable
Integration and interoperation
Cloudified
Community Driven")
Notes - Slide 2
ReDBox is a Research Data Management Platform. It assists researchers and institutions to plan, create and publish their research data assets.
- It is proudly open source.
- It is managed and supported by the QCIF Engineering Services team.
- It is fully customisable.
- It is an integration platform, it will join your platforms together. It is interoperable, your platforms will happily exchange information with ReDBox.
- It is in the cloud: mostly, we are progressively increasing our cloud options.
- But most important is that it is community driven, the work we do to continuously improve ReDBox is determined, prioritised and often contributed by our community.

Notes - Slide 3
ReDBox has a rich history, with ongoing support from the Australian eResearch sector. Originally ReDBox was created on top of the Fascinator platform by USQ back in 2010 and taken up by successive institutions under the ANDS Metadata Stores funding program. In 2012 QCIF took over the management of ReDBox, giving it a stable non-partisan home. 2015 saw our first cloud version in ReDBox Lite, last year we produced our first SaaS version with the RAPportal, and this year we are releasing ReDBox 2.

Notes - Slide 4
This slide shows the institutions we know are using ReDBOX. The ones above the line have support contract with QCIF which help to pay for maintenance and enhancement of the software.

Notes - Slide 5
At its core ReDBox is a customisable research data registry, providing forms, workflows and system integrations to assist institutions in creating and managing the metadata describing research data collections. It includes the innovative Mint platform to provide a name-authority lookup service for researcher information and project details, as well as commonly used research classifications, such as FOR codes. Mint helps to create high quality linked-data metadata, by supplying URIs as metadata values rather than strings which can be error-prone and ambiguous.
It incorporates a Data Management Planning tool, curation functions and a flexible harvester tool to pull data in from external platforms. It is a schemaless forms driven platform, incorporating configurable transformers to generate metadata from a standard schema, like RIF/CS or DataCite Citation format.
ReDBox includes a full set of APIs and provides an OAI-PMH interface for metadata harvesting by repositories including Research Data Australia.

Easy to configure forms
New object model (JSON-LD in MongoDB)
Modular/plug-in architecture
Multi-institutional RBaaS (e.g. RAPortal.org.au)
DLC (Data LifeCycle) support via RAiDs
maDMPs
Workspace concept to manage resources and datasets
Flexible storage provisioning with the UTS Provisioner Framework
Dataset harvesting, archiving (OCFL) and publishing
Comprehensive search/discovery tool</p>
<p>")
Notes - Slide 6
In late 2017 QCIF embarked upon a complete refresh of the ReDBox technology stack, assisted by RDS and UTS. We threw out the clunky front end tech stack and used Angular.js, a javascript framework that hasn’t gone off overnight. We have created a form configuration process to let you create your own forms and style them using bootstrap. It is easy to extend functionality using a plugin architecture. We can deploy it so multiple institutions to run off a hosted version of ReDBox, our ReDBox as a Service offering. The DMP tool now supports Machine Actionable DMPs. We have introduced a Workspace concept for managing resources within ReDBox. And with UTS we are implementing provisioning, data harvesting and rewriting the search/discovery tool.

Notes - Slide 7
And this is where the Data Life Cycle is supported. It allows users to plan for their data, acquire the resources for storing their data, harvest file level data and metadata back into ReDBox, curate it, archive it, publish it and make it discoverable.

Notes - Slide 8
Mercifully for you, this is not a demo. This is just a screen shot of a full blown DMP, with the DMP components organised in a tabular form. At this point I will remind everyone that it is fully configurable and that the forms can be as minimal or extensive as you require.

Notes - Slide 9
An example of the minimum form is the Research Activity Portal (RAP). The RAP is our first configurable SaaS platform. It is a proto-DMP designed for users to register their research activity in order to get a RAiD, which is a Research Activity ID. It is available nationally in Australia and supports institutional views, so an individual institution can have a RAP themed to their institution with customised forms.

Notes - Slide 10
At this point Petie took over the talking.
The next few slides go through some of the principles behind the service-provisioning aspect of ReDBOX.
 want
Improved ability to do
high-integrity high-impact research")
Notes - Slide 11
We try to appeal to Researcher’s better selves: who doesn’t want to do high integrity research that has high impact?
Knowing where your data are is obviously key to Research Integrity, and is mandated by research norms, codes of practice and by funders. The provisioner helps with this; because provisioning can be invoked from a Research Data Management Plan (RDMP), the provisioned research space - we call them workspaces - has a bit of metadata that points back to the RDMP, which carries details about authorship, ownership of rights, retention requirements etc.
We also try to improve research impact - by making data available with as much provenance as possible to encourage re-use.

Notes - Slide 12
“An army of bots” is not really a principle, the principle is that everything possible should be done to automatically capture research data where it is and link it back to its custodian, and to metadata about the context in which the data were collected, curated or created. In the eResearch team at UTS we have long experience with customer requests such as “can we make sure that every student has a file-share to which the supervising panel also has read access even as the supervisors change” or “can I have an eNotebook for every PhD candidate in my department”. The provisioner will help with this kind of automation and more; we want to do things like report on how many electronic notebooks or git repositories are owned by the staff and students in a cohort that are NOT linked to an RDMP.

Notes - Slide 13
When we started work on what became the Provisioner module of ReDBOX we were looking at how to integrate data applications that house research workspaces. For example how might we assist researchers in moving - maybe by reference rather than copying - data from a project in a microsocope-image database to the storage service in a visualization facility so the developers there can work on analytics and visualizations, and then archive the original data, code and outputs of the viz process? When we considered the scope of this and that we might be supporting dozens of applications that provide workspaces over the next few years, and working more loosely with hundreds more we realiased that we didn’t want to be doing n * n integrations, where n is the number of research apps we support. We looked to standards for managing data.

Notes - Slide 14
One of the key standards was a way of moving “packages” of research data, where a package might mean a zip file, a manifest of data-by-reference or a directory of well-described data on a file share. From this search was born DataCrate - a specification which links together several existing standards into what we think is a best-practice generic way to ship and display research data.
This screenshot is of a the index.html file from a DataCrate which you can take a look at online or download as a zip file.

Notes - Slide 15
You can read more about the spec at github and in the presentation I (Petie) gave at OR2018.
Summary: It uses BagIt for organizing files with checksums, JSON-LD for high-fidelity extensible metadata (linked data in JSON format), uses the schema.org vocabulary where possible for general metadata (dates, places, people) and specifies where to look for terms that are not covered by schema.org.
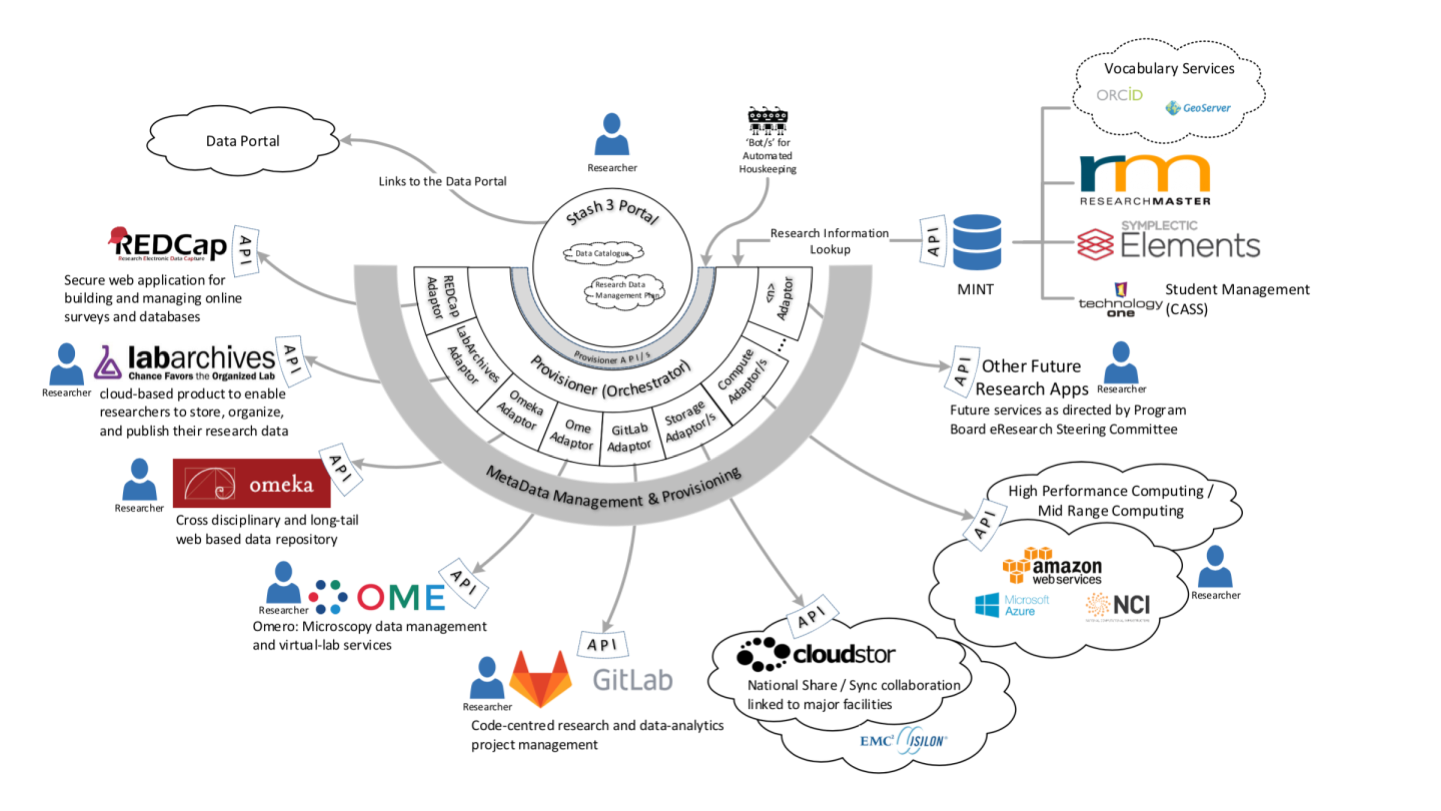
Notes - Slide 16
This diagram is a highly abstracted view of the UTS architecture for research-data management. Researchers are shown in many places in this diagram to emphasise, that while they can use the Stash (ReDBox) portal to edit Research Data Management Plans, and describe data sets, them can ALSO continue to use research workspaces independently. We aim to have an army of ‘provisioner bots’ working to help keep track of this.
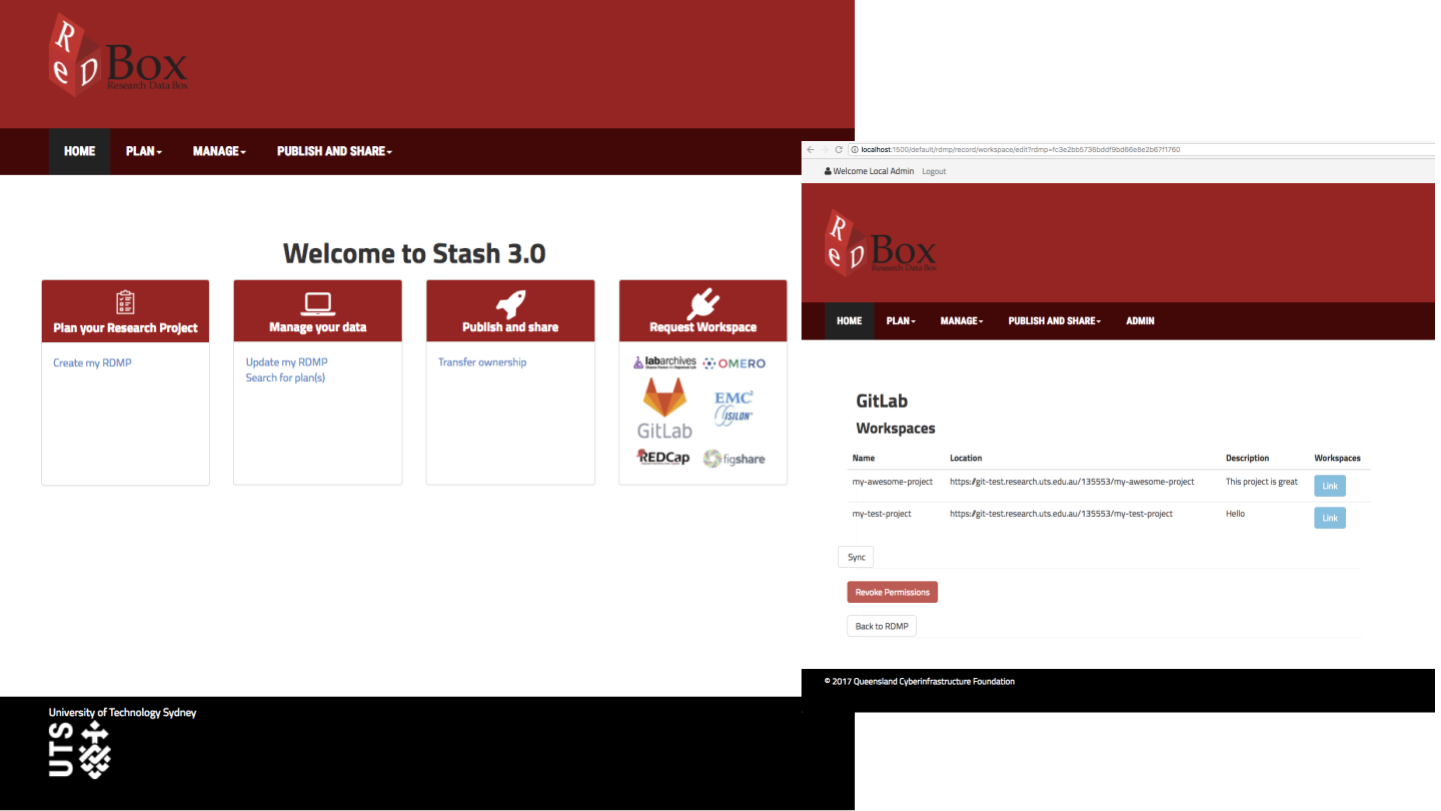
Notes - Slide 17
This is a mock-up of the Redbox 2.0 functionality showing the way researchers will be able to manage the research process, creating data management plans and requesting workspaces, as well as identifying existing workspaces and linking to them. The right-hand screenshot shows how gitlab projects can be linked to a Research Data Management Plan as workspaces.

Notes - Slide 18
This animation shows how a researcher will create a new workspace - in this case a gitlab repository. The Provisioner uses the gitlab API to connect as the user, create a new project/workspace, and leaves behind a calling card which links the project back to the RDMP. Later, the researcher will be able to archive and maybe publish this data via Provisioner, and it will know where to find the data.
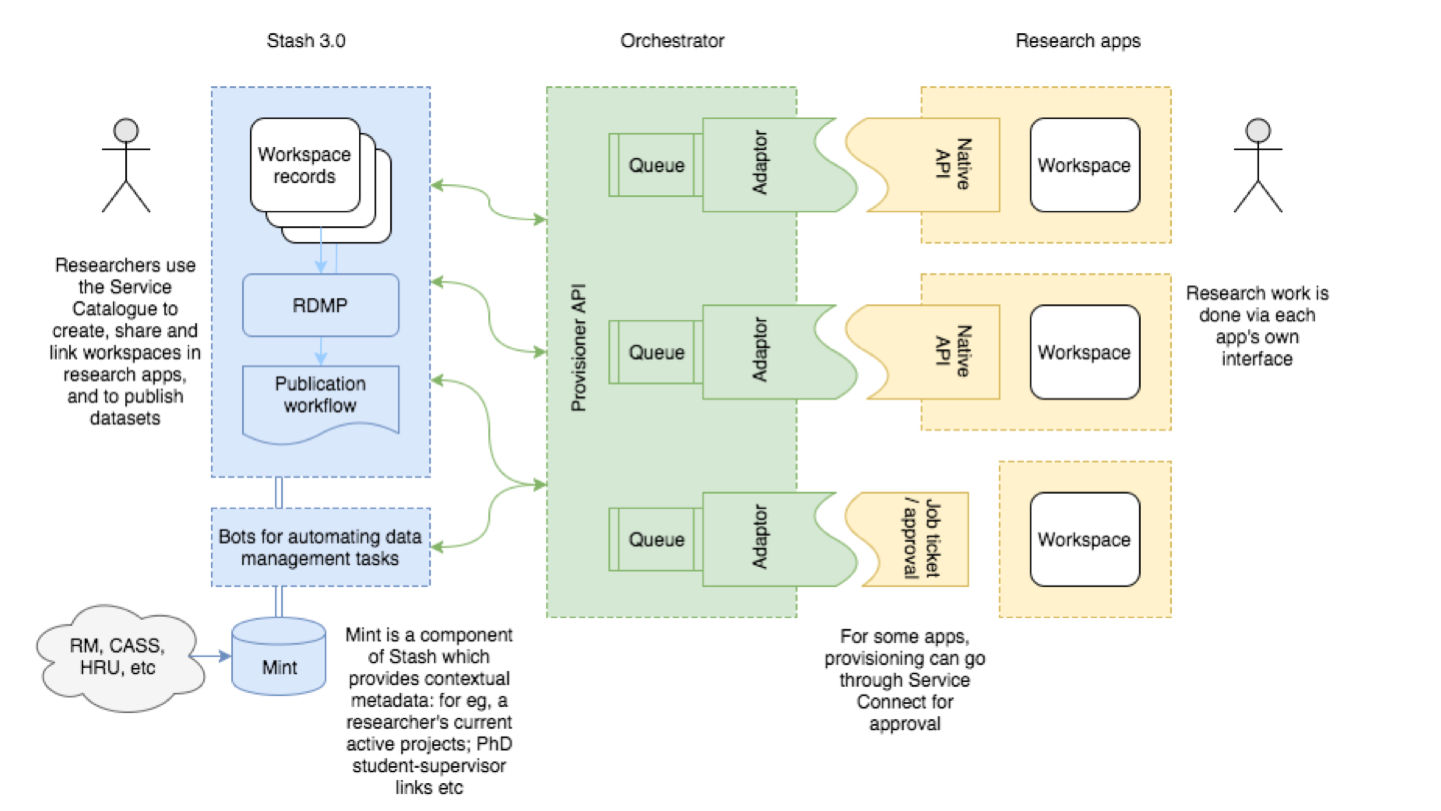
Notes - Slide 19
This diagram shows how Research apps will be loosely coupled with Stash (the UTS name for our data management system that runs ReDBOX).
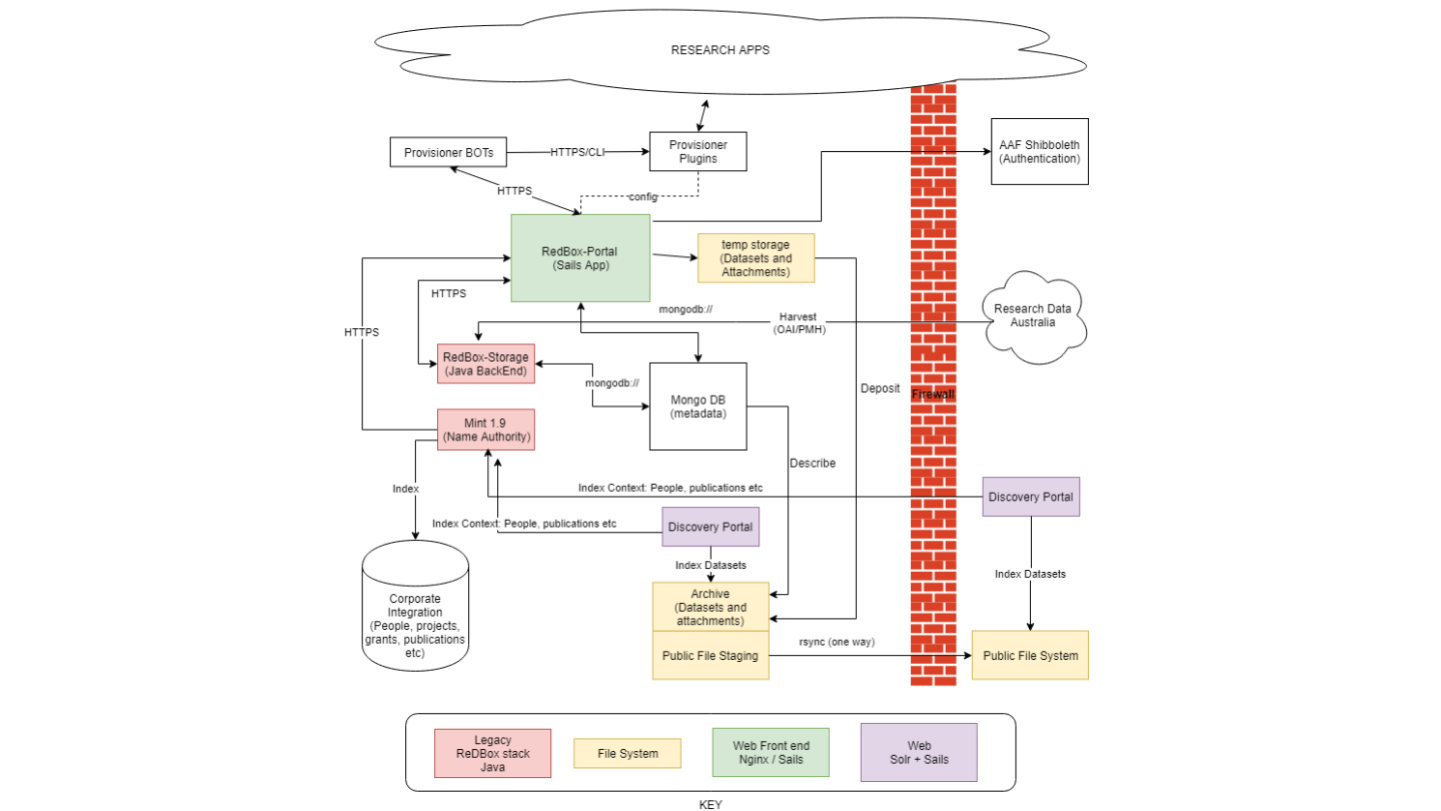
Notes - Slide 20
This diagram shows the technical architecture of the system. The “Repository” is actually several loosely coupled sub systems. The UTS implementation of ReDBox 2 will be a kind of “deconstructed” repository with the functions we see in more monolithic software such as DSPace or Samvera residing in different places. For example ReDBox is about data and workspace management, but the Data resides in research apps and in a static file-based archive, and the public-facing discovery service will be a separate application (which we’re working on at the moment).

National data catalogue
Actionable Service Catalogue
(inter)National DMP
Open data workflows
Generate project portals")
Notes - Slide 21
This slide lists some of the future possibilities for ReDBox - we’re particularly interested in its potential at a national or consortial level.

Notes - Slide 22
Finally (from Gavin) some words on sustainability.
ReDBox is free open source software and you can download and run it today. But
-
QCIF is a not for profit organisation that can’t afford to cover the costs of ReDBox and the NCRIS grants are a distant memory.
-
So we have multiple models for subscribing to a support service. This covers our maintenance costs.
-
We fund development through projects like our collaboration with UTS.
-
We offer increasingly commercial services like managed hosting of ReDBox.
-
We are rolling out the Software as a Service (SaaS) version with a transactional charging model, subject ot feedback, next year.
-
We depend on our community and free and open communication with our community, so we know what each are doing.
-
And we depend on our community to drive the direction of ReDBox.

Notes - Slide 23
If you would like to know more please check out our website.