Implementing ORCID and other linked-data metadata in repositories
2015-04-14
Implementing linked data metadata systems
Peter Sefton
University of Technology, Sydney
The ORCID site says:
ORCID provides a persistent digital identifier that distinguishes you from every other researcher and, through integration in key research workflows such as manuscript and grant submission, supports automated linkages between you and your professional activities ensuring that your work is recognized.
I will post this so I can present - and come back later to expand, and clean up typos, so this post will evolve a bit.
This event is launching a document:
The ‘Joint Statement of Principle: ORCID - Connecting Researchers and Research' [PDF 297KB] proposes that Australia's research sector broadly embrace the use of ORCID (Open Researcher and Contributor ID) as a common researcher identifier. The statement was drafted by a small working group coordinated by the Australian National Data Service (ANDS) comprised of representatives from Universities Australia (UA), the Council of Australian University Librarians (CAUL) and the Australasian Research Management Society (ARMS). Representatives of the Australian Research Council and the National Health and Medical Research Council also provided input through the working group.
In this presentation I talk about some of the details of how to implement the ORCID. Just how do you use an ORCID ID in a institutional repository?
This is not that simple, as most of our systems are set up to expect string-values for names, not IDs.
This talk is not all about ORCIDs...
... it's about implemeting linked data principles
This talk is about why ORCIDs are important, as part of the linked-data web. I will give examples of some of the work that's going on at UTS and other institutions on linked-data approaches to research data management and research data publishing and conclude with some comments about the kinds of services I think ORCID needs to offer.
Modern metadata should be linked-data
Thou Shalt Have No Data Without Metadata
RDF is best practice for Metadata
Use Metadata Standards where they exist
Use URIs rather than Scalars (eg Strings) as names
Name all data and metadata ASAP
And while it's easy enought to say "RDF is best practice for Metadata" entering RDF metadata is non-trivial for humans. So I wanted to show you some of the work we've been doing to make it possible to build research data systems that are compliant with the above principles.
1. ReDBOX
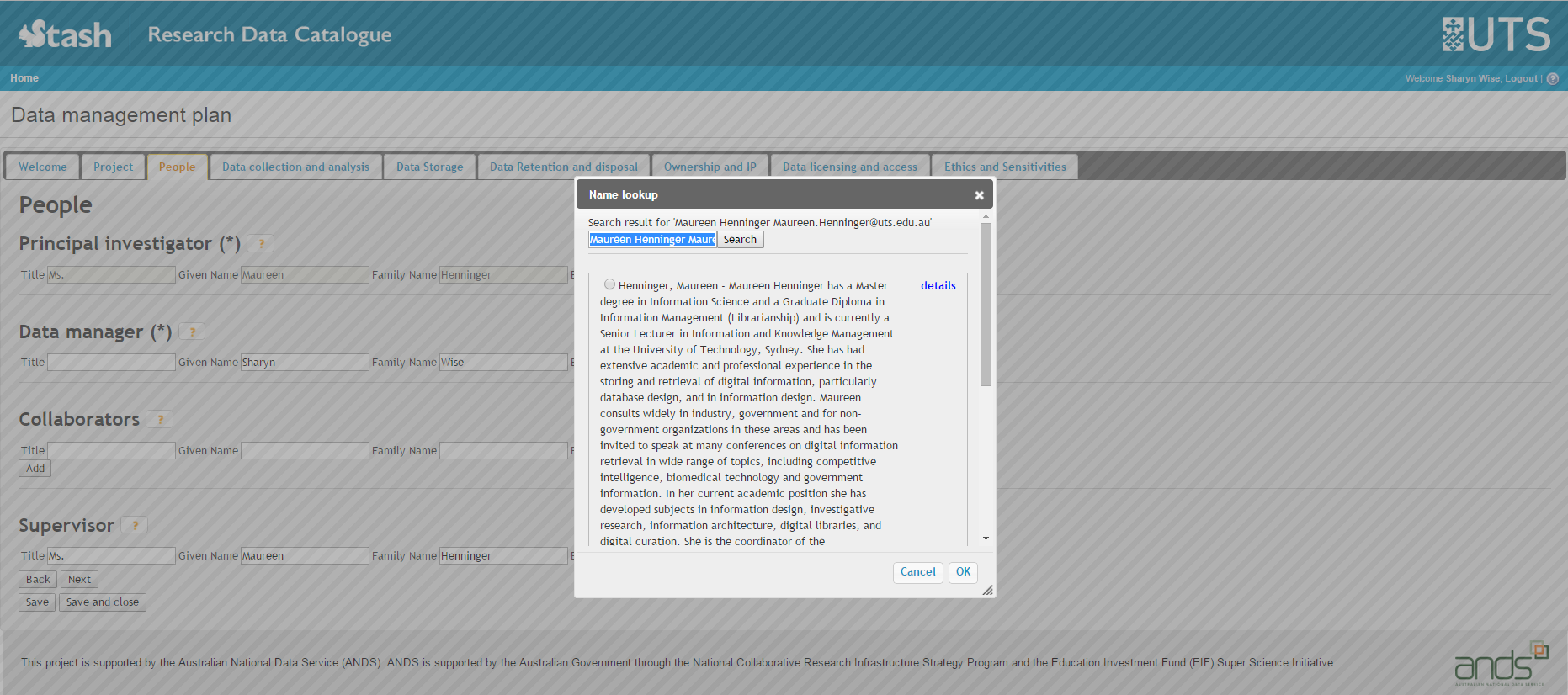
Screenshot from the UTS Stash data catalogue showing a party lookup, to get a URI that identifies a person.
But, the ReBOX/Mint partnership is a very close one, there's no general way to lookup other name authorities, without loading them into Mint.
In 2014 I asked, what if there were a general way to do this, so that we could use URIs from a wide range of sources, and a team of developers from NZ and the UK responded as part of the Developer Challenge Event at that year's Open Repositories conference in Helsinki, supported by Rob Peters from ORCID, who is at this meeting in Canberra.
Slide by:
- Adam Field : iSolutions, University of Southampton
- Claire Knowles: Library Digital Development Manager, University of Edinburgh
- Kim Shepherd: Digital Development, University of Auckland Library
- Jared Watts: Digital Development, University of Auckland Library
- Jiadi Yao: EPrints Services, University of Southampton
Enter Fill my List
 Members of the Fill My List team (minus Claire Knowles who took the pic)
hard at work at Open Repositories 2014
Members of the Fill My List team (minus Claire Knowles who took the pic)
hard at work at Open Repositories 2014
See their git repo.
This modest github repository might not look like much, but as far as I know, it's the first example of an attempt to create an easy-to use protocol for web developers to make lookup services.
Fill my list enabled auto-complete lookup to multiple sources of truth including ORCID, so a user can find the particular Lee or Smith they want to assert is a creator of a work, specify which kind of Python they mean for the subject of a work and get a URI. The FML team did prototype implementations for ePrints and Dspace software.
Looking up the Schools Online Thesaurus (ScOT) for the URI for "Billabongs".
!!!SPOILER ALERT!!!
it's http://vocabulary.curriculum.edu.au/scot/9962
The above screenshot shows a prototype lookup service which shows auto-complete hints as you type.
Note that typing "Oxb" find the same URI - Billabongs are also know as 'oxbow lakes'.
Note that in the screenshot you can see one of the important changes we made to the Omeka repository software to support linked data, as part of the Ozmeka project.
Instead of just a string field for the subject there is a URI as well. So, even though some records might say "Billabongs" and some might say "Oxbow lakes" both would have the same URI.
Note that to make this work we had to hack the Omeka software we're using because like most repository software it didn't have good support for using URIs as metadata values.
So, why am I telling you all this?
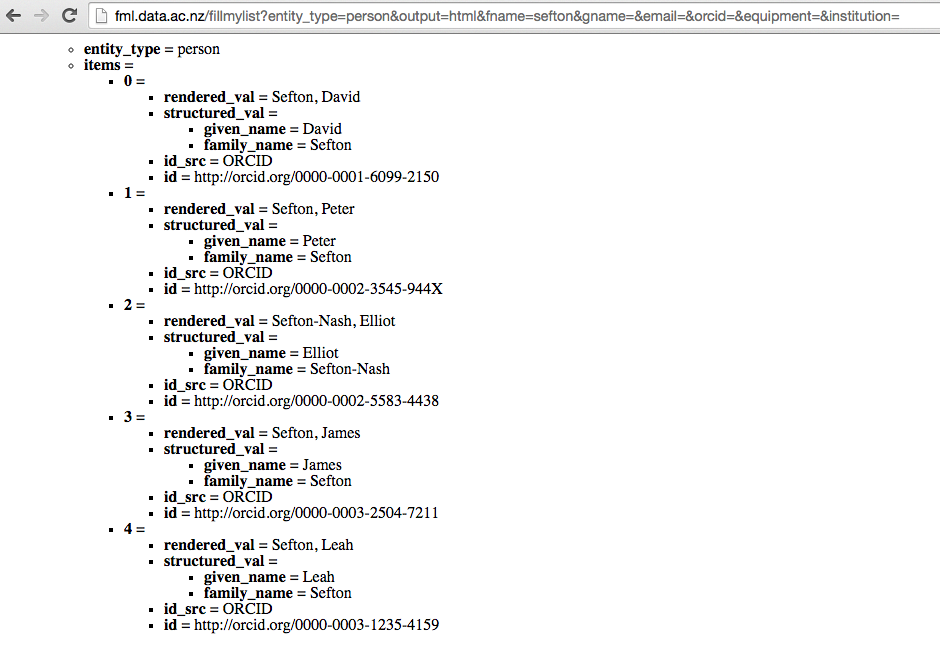
The raw, machine-readable Fill My List protocol in action, looking up an ORCID index.
When we refer to researchers on the web, we should use their ORCID ID, in the form of a URI. But to be able to do this we often have to update repository software (as my tean at UTS are doing with Omeka).
In conclusion
The ORCID API (machine to machine interface) provides pretty good but not perfect open lookup services so...
Repository developers can make their repositories linked-data compliant
But it's a lot of work and it will involve a community effort to update our repository systems, many of which are open source.
Now, a few years later, the government is making its own URIs and the Australian National Data services is providing vocab services.
ORCID does have a public API to allow us to build Fill My List type lookup services - allowing to query on name-parts, it would be better if it included bibliographic information, wich might help someone entering metadata choose between two people with the same name.