I was invited to speak at the National Higher Education Faculty Research Summit in Sydney on May 22 about our Research Data Repository project. The conference promises to provide a forum for exploration.
Explore
Sourcing extra grant funding and increasing revenue streams
Fostering collaboration and building successful relationships
Emerging tools and efficient practices for maintaining research efficacy and integrity
Improving your University’s research performance, skills and culture to enable academic excellence
My topic is “Introducing a data deposit management plan to the research community at UWS”. This relates directly to the conference theme I have highlighted, on emerging tools and practice. My strategy for this presentation, given that we’re at a summit, is to stay above 8000m, use a few metaphors, and discuss the strategy we’re taking at UWS rather than dive too deeply into the sordid details of projects. As usual, these are my notes; I hope these few paragraphs will be more useful than just a slide deck, but this is not a fully developed essay.
There are two kinds of data: Working and Archival/Published
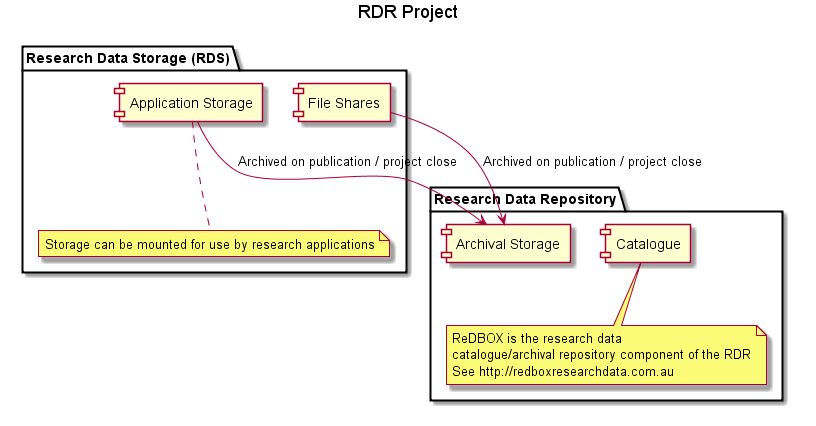
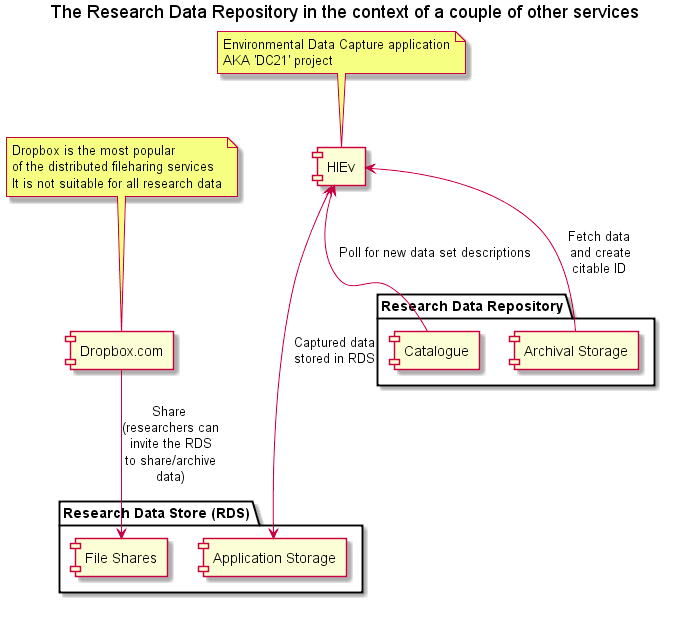
This talk is not going to be all about architecture diagrams but here’s one more, from a recent project update showing two examples of applications that will assist researchers in working with data. One very important application is HIEv, the central data capture/management platform for the Hawkesbury Institute for the Environment. This is where research teams capture sensor data, research support staff work to clean and package the data, researchers develop models and produce derived data and visualisations. We’re still working out exactly how this will work as publications using the data start to flow, but right now data moves from the working space to the archival space, and thence to the national data discovery service, see this example of weather data – (unfortunately the data set is not yet openly available for this one, I think it should be, and I’ll be doing what I can to make it so).
Data wrangling services
Data management
Some key points for this presentation
I want to talk about:
-
Governance, open access, metadata, identifiers
-
The importance of the (administrative) research lifecycle
-
Policy supported by services rather than aspirations
eResearch = goat tracks

Groups like mine work in the gap between the concrete and the goat track, my job is to encourage the goats.
And once we’ve encouraged the goats to make new paths, we need to get the university infrastructure people to come and pave the paths.
What’s over the horizon?

-
Changes in the research landscape – more emphasis on data reuse and citation, increasing emphasis on defensible research mean data will become as important as citations
-
Providing access to publications and data so it can be reused.
-
(e)Research infrastructure in general, where collaboration must not be constrained by the boundaries of individual institutional networks and firewalls.
Any others?
Research data, Next Big Thing?
Governments are joining in
-
Stop the fat multinational-publisher tail from wagging the starving research dog. Ensure research funded by us is accessible and usable by us.
-
Understand our researchers and their habits, so we can help them take on this new data management responsibility (actually it’s not a new responsibility, but many have simply been paying no attention to it, in the absence of any obvious reason to do so).
-
Sort out the metadata mess most universities are swimming in.
Now for the big picture stuff.
## ~~Open~~ Free scholarship is coming? (Just beyond that ridge)
## OA is a Good Thing, Which will:
Reduce extortionate journal pricing.
Provide equitable access to research outputs to the whole world.
Open Access to publications and Coming Soon: Open Access to data.
Promote Open Science and Open Research.
Drive huge demand for data management, cataloguing, archiving, publishing services
## http://aoasg.org.au/

There are competing models for open access. Bizarrely the discussion is often framed as a contest between ‘Green’ and ‘Gold’. It’s a lot like the State of Origin Rugby League, a contrived but popular-in-obscure-corners of the world contest where the ‘Blues’ and ‘Maroons’ run repeatedly into each other. In both State of Origin and Open Access, the current winners are large media companies. Add least being an Open Access advocate doesn’t give you head injuries.
Green OA refers to author-deposited pre-publication versions of research articles. Gold means that the published version itself is ‘Open’ for some ill-defined definition of open, often at a cost of thousands of dollars, out of the researcher’s budget. Green or Gold, a lot of so-called Open Access publishing operates with no formal legal underpinnings, that is, without copyright-based licenses. For example when I deposited a Green version of a paper I had written here, and wrote to the publisher asking them to clarify copyright and licensing issues I got no reply.
We have a brief window now to try to build services for research data
management that do have a solid legal basis and avoid following some of
the OA movements missteps but this is not trivial (1).
Identity management is crucial

Like the rest of us, this dog has all sorts of identifying names and numbers – a microchip number linked to a database, an ID assigned by the RSPCA, patient numbers at veterinary practices, which may be linked to more than one human, phone numbers on his tag etc. Point is, it’s much worse for researchers than for dogs – identities are maintained all over the place. Foley and Kochalko put it like this:
While much has changed since the days of David Livingstone, we continue to struggle with associating individuals with their works accurately and unambiguously. Author name ambiguity plagues science and scholarship: when researchers are not properly identified and credited for their work, dead-ends and information gaps emerge. The impact ripples throughout the ecosystem, compromising collaboration networks, impact metrics, “smarter” research allocations, and the overall discovery process. Name ambiguity also weighs on the system by creating significant hidden costs for all stakeholders. (2)
To do metadata management well we need to make sure that we sort out all
sorts of naming and identifying issues, dealing correctly with potential
causes of confusion, multiple people with the same name, people with
multiple names over time, and simultaneously, name variants. Even where
there are agreed subject codes like the Field of Research codes that are
heavily used in research measurement exercises they can get mixed us as
different databases use different variants.
We try to work out how to fit new processes into existing workflows
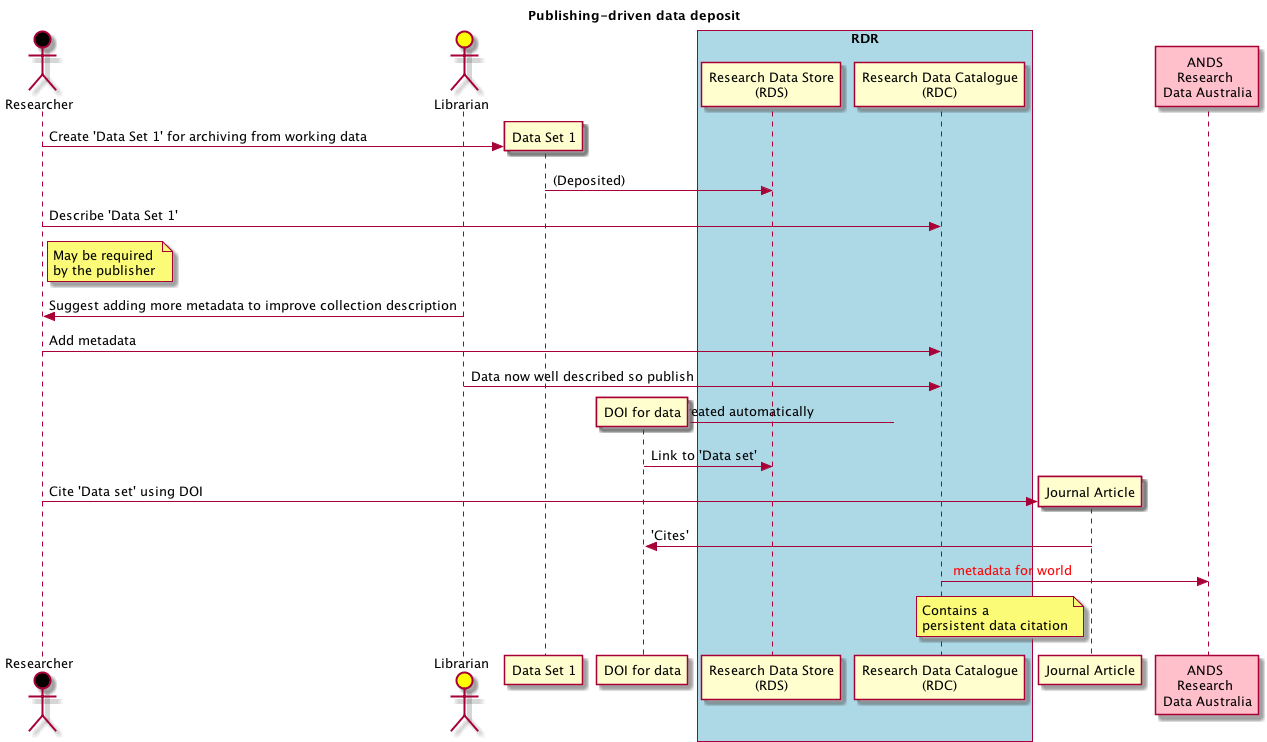
For example, the above scenario tries to capture the interactions that
would happen when a researcher is required by a journal to deposit data
before publication. We spend a lot of time talking to the Office of
Research Services (ORS) and research librarian team about how we can fit
in with their existing processes, and how to minimise negative impacts
on research groups. Research Offices are used to responding to changing
regulatory environments so adding new fields to forms etc is
straightforward. Changing IT services is much harder; the ITS is much
bigger than ORS, new services need to be acquired, provisioned and
documented, and the service desk team has to be taught new processes.
Challenge: how to stop the corporate publishing tail from wagging the scholarly dog

-
Policy on ‘ownership’ of intellectual property rights over data needs to be established. This is not as simple as it is for publications, as data are not always subject to copyright (1).
-
Data citation is going to be an important metric.
New models are needed. People like Alex Holcombe from Sydney uni are developing them:
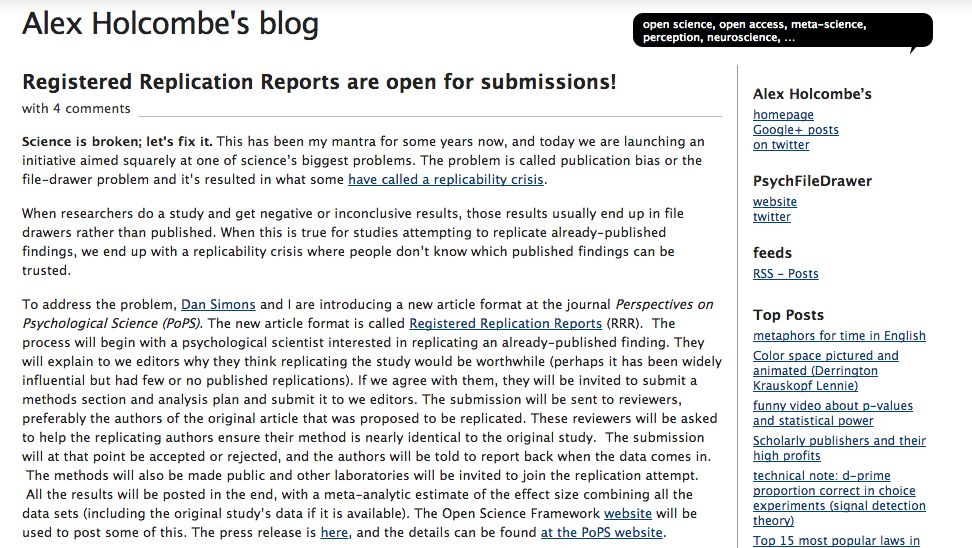
Science is broken; let’s fix it. This has been my mantra for some years now, and today we are launching an initiative aimed squarely at one of science’s biggest problems. The problem is called publication bias or the file-drawer problem and it’s resulted in what some have called a replicability crisis.
When researchers do a study and get negative or inconclusive results, those results usually end up in file drawers rather than published. When this is true for studies attempting to replicate already-published findings, we end up with a replicability crisis where people don’t know which published findings can be trusted.
To address the problem, Dan Simons and I are introducing a new article format at the journal Perspectives on Psychological Science (PoPS). The new article format is called Registered Replication Reports (RRR). The process will begin with a psychological scientist interested in replicating an already-published finding. They will explain to we editors why they think replicating the study would be worthwhile (perhaps it has been widely influential but had few or no published replications). If we agree with them, they will be invited to submit a methods section and analysis plan and submit it to we editors. The submission will be sent to reviewers, preferably the authors of the original article that was proposed to be replicated. These reviewers will be asked to help the replicating authors ensure their method is nearly identical to the original study. The submission will at that point be accepted or rejected, and the authors will be told to report back when the data comes in. The methods will also be made public and other laboratories will be invited to join the replication attempt. All the results will be posted in the end, with a meta-analytic estimate of the effect size combining all the data sets (including the original study’s data if it is available). The Open Science Framework website will be used to post some of this. The press release is here, and the details can be found at the PoPS website.
This seems like a positive note on which to end. Hundreds of researchers are trying to fix scholarship, they’re the ones we need to talk to about what a data repository or a data management plan should be.
Science is broken let’s fix it