Culture and climate
I was invited to attend the planning day for the Institute for Culture and Society (ICS) at the University of Western Sydney, to talk about the eResearch team at UWS, discuss collaboration tools, and show a few useful, relevant examples of eResearch in the humanities.
Here are some rough notes for the discussion.
For eResearch I will talk about our small eResearch website, and on the subject of collaboration tools I’ll be evasive.
The problem with surveys of collaboration tools
While lots of people are interested in finding out how to collaborate using modern techniques we really need to talk this through on a project by project basis. I tried to write about collaboration tools at the Australian Digital Futures Institute after complaints from an education researcher in the institute about the bewildering array of stuff we used to get things done. I gather it was like turning up for work as a carpenter’s apprentice and being introduced to all the tools in the ute at once.
(That piece is still online, but it is of historical interest only, as the tools have all changed. Not to mention it is very long winded and mentions some USQ tools that aren’t relevant to you, still if you’d like to see how I explained Twitter and hashtags, and predicted the demise of Google Docs ‘cos Google Wave had arrived then you might enjoy it. Otherwise, file as too long, don’t read.)
Dr Sefton’s quick cure for a lack of online collaboration
If in doubt, start a Google Group. If symptoms persist, see me in the morning; I may put you into one of my group therapy sessions.
Some collaboration modes/tasks
-
Talking to each other: email, video/audio conferencing, discussions
-
Writing together: word processing, wikis, Content Management Systems
-
Publishing: blogs, wikis, Content Management Systems, pod/video-casting, CVs, microblogging
-
Remembering and sharing: links, reference materials, bibliographic references
-
Storing: stuff
Which tools do you favour and why?
eResearch for Culture and Society
Back to the more interesting topic – eResearch as it relates to culture and society.
On the way to work on Monday I rode through local instances of some lovely spring weather (cold enough for me to want a jacket descending the mountains, warm by the time I got to the river), which got me thinking about the climate and in turn the Hawkesbury Institute for the Environment (HIE), which is just downstream from Penrith.
The eResearch team does a lot of work with HIE and the connection is easy to see. We obviously need large amounts of data to document, let alone model, climate, and we need to run climate simulations at atmospheric and oceanic scale as well as at smaller scale, like models of leaves or trees – all of which involves data management, computational tools and global collaboration.
Weather, climate, and the ICS planning day reminded me of an analogy of Michael Halliday’s:
We can perhaps use an analogy from the physical world: the difference between “culture” and “situation” is rather like that between the “climate” and the “weather”.
Then I was introduced to corpus linguistics in the early 1990s in a workshop by John Sinclair. In the workshop multiple instances of words in context were used as data to help decide what they actually mean. The Collins COBUILD dictionaries that Sinclair was involved in producing gave quite a different picture of the ‘climate’ of English that the traditional dictionary approach of forward-copying definitions by using, you know, evidence to decide what words mean.
Fast forward to 2012 and the Macquarie dictionary decided to re-look at its definition of misogyny, after the word got a bit of an airing in the Australian Parliament, as noted in this letter from the Macquarie’s editor. I knew that they would have been able to get plenty of data on the term’s use, and I thought of John Sinclair again. But the letter didn’t talk about data, curiously, it talked about house-work.
As Editor of the Macquarie Dictionary, I picture myself as the woman with the broom and mop and bucket cleaning the language off the floor after the party is over.
The dictionary is one sort of ‘cultural climate’ record, so of course we have to have sceptics, like this example form the Herald Sun’s Patrick Carlyon, who like a good climate change sceptic brings his own data to the table.
Given the ever-changing flow of words and their meaning, Macquarie has announced a raft of further definition shadings to reflect recent political events and current affairs:
Dog: To be known also as "cat", after a two-year-old boy at an East Brighton childcare centre pointed at a chihuahua and meowed.
These days, dictionary editors don’t need no fancy ‘corpus’ like they used on those revolutionary Collins Dictionaries, as we find out from another letter they have the Internets, and not only that, they can still copy from others, just like they used to.
When it is brought to our attention, we are lucky these days to be able to draw on the immense resources of the internet such as newsfeeds, blogs, videos, etc., to research the use of the word over time, in different areas of the world, and in different kinds of texts. Of course, we can also check other dictionaries, to see if the same conclusions have been reached by our fellow lexicographers.
http://www.macquariedictionary.com.au/pdf/editors_response.pdf
I’m telling you this because I wanted to show a simple eResearch example from the cultural sphere. Halliday’s climate analogy seemed apt. Just as we know climate science is done with lots of data points, recording the weather at the highest possible scale that add up to a climate record, we can study cultural phenomena such as language by looking at data-points of various kinds. Text is an easy example, because it’s easy to search and there’s now a lot of it to search.
Anyway, with all that in mind, I wanted to ask the researchers from the institute:
What infrastructure do you need to do ‘culture science’?
Or is that a stupid/naïve/offensive question?
While people think about that I thought I’d continue with a few examples, and come back to the discussion of collaboration and eResearch tools at the end.
The Feds don’t seem to think this idea of ‘culture science’ it is entirely stupid, as they have funded a couple of million-dollar plus projects to build virtual laboratories, not just in sciences but in the humanities.
NeCTAR (Aus govt funding) Round 1 Virtual lab projects
-
>>> Humanities Networked Infrastructure (HuNI) unlocking and uniting Australia's cultural data <<< This one relates to culture
-
The Characterisation Virtual Laboratory: research environments for exploring inner space
A question for ICS researchers – what kind of cultural data is important to you?
Round 2 Virtual Laboratories recommended for funding
ul>
QueryPic showing searches for Asia and Asian in Trove Newspapers 1803–1954
http://dhistory.org/querypic/4t/
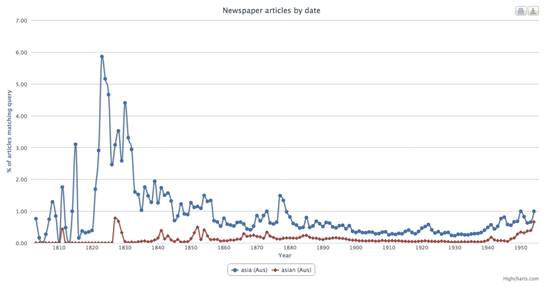
You can click on a data point to see a list of articles.

But be careful with these results!
Q. Why were the Aussie papers talking about Asia so much in 1820?
A. They were talking about a ship.
If only the Macquarie had something like this.
(There are some issues with this tool, not least of which is that this is not a stable, fixed data set, people are actively improving it via crowdsourced editing, and the data set is expanding so it would be impossible to reproduce results. I’ve suggested that a solution would be to place snapshots of the data into the Research Data Storage Infrastructure starting to roll out now via lead agency, The University of Queensland so that researchers could work on known-stable corpora, and perform tricks like reindexing to improve performance on this class of query.)
Contrast this approach of re-using existing data in a fairly generic database to ask new questions with a very different kind of eResearch application, the Dictionary of Sydney, a project of the Arts Computing Lab at the University of Sydney; we can search for the Art Gallery of NSW where we’ll be meeting, and from there browse a rich curated web of relationships between entries about buildings, people, institutions etc.
Another way of recording culture: The Dictionary of Sydney
http://dictionaryofsydney.org/organisation/art_gallery_of_new_south_wales
So, back to the question.
What infrastructure do you need to do ‘culture science’?
[Updated 2012-11-13, removed Andrew Leahy as co author]