Think local, act global: Institutional Data Repositories being built in Australia with lessons learned from Institutional Publications Repositories
2012-07-24
Slide 1
This short presentation from Open Repositories 2012 is “Local in, Global Out” Copyright Peter Sefton, Vicki Picasso, Anna Shadbolt, Simon Porter and Caroline Drury. This work is licensed under a Creative Commons Attribution 3.0 Australia License. Images used in this presentation are copyright the presenters unless otherwise noted.

Slide 2
In this talk we're going to look at the change in architecture that we're seeing as repositories mature and talk about the work that's going on in Australia to build a new wave of Institutional data repositories.

Slide 3
We'll refer to the first wave of institutional repositories as "IPRs" rather than just IRs - the P is for "Publications". Many IPRS are almost exclusively collections of PDF files. Digital versions of the stacks of paper managed by the libraries that run the repositories. (This is the local National Library).

Slide 4
Without wanting to sound too much like the Repository Rat, Dorothea Salo and her 'roach motel ( “Innkeeper at the Roach Motel.” Library Trends 57, no. 2 (2008): 98–123.) ', the first IPRs could be characterised as monolithic containers. You can put things in, and check them out, and there is a batch download facility in the form of OAI-PMH. Of course IPRs have moved on from the first self-deposit systems like ePrints a decade ago.

Slide 5
IPRs have in many cases become sites for activities other than deposit/retrieve, although there is now a big question mark over their role in a potential new Open Access scholarly communications process. As the landscape changes they will need to evolve, as libraries have done. (Anna Shadbolt points out that there is a banner missing here on this library: Win an IPad!)

Slide 6
Some important background: In Australia the government has invested in research infrastructure. Earlier waves of cash gave us IPRs at every institution. Now the push is to build IDRs where D is for data. Not everyone talks about repositories in this space now though. Why? because this time the money is split across multiple government funded projects which are not 100% aligned: data storage is funded separately from data registries/catalogue, so many have not conceptualised the infrastructure as a repository with storage and catalogue services together.

Slide 7
One of the problems that we had with IPRs was that the local use of metadata, particularly terms for things like subjects, and strings to refer to people, was not standardised. The situation with metadata in IPRs is rather like our multiple railway gauges nationally (we weren't always one country and change is expensive if you try to do it too late.) As we start to work on IDRs the Australian National Data Service (one of the groups handing out cash) is trying to improve the way data is described across all IDRs, to try to prevent too many problems down the ‘track’.
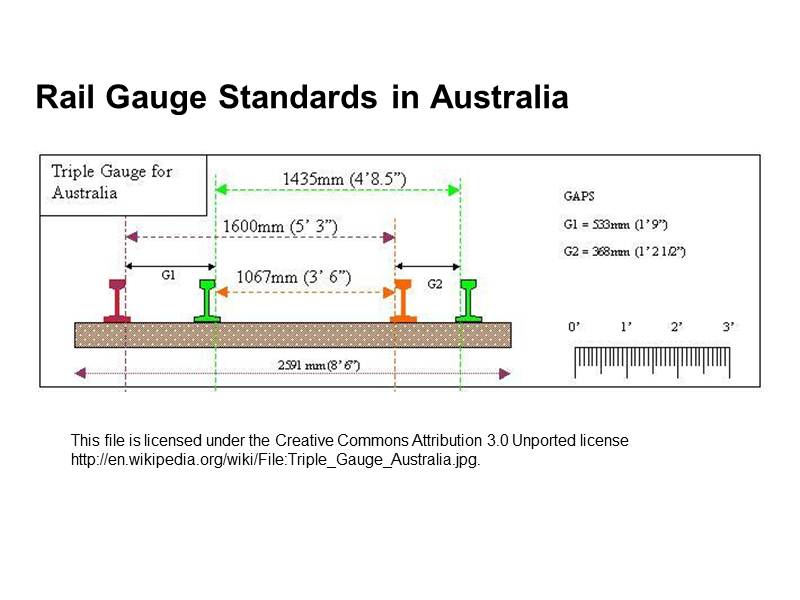
Slide 8
When you're trying to build an aggregation service standardisation becomes a problem. This is Research Data Australia, run by the Australian National Data Service. http://researchdata.ands.org.au/
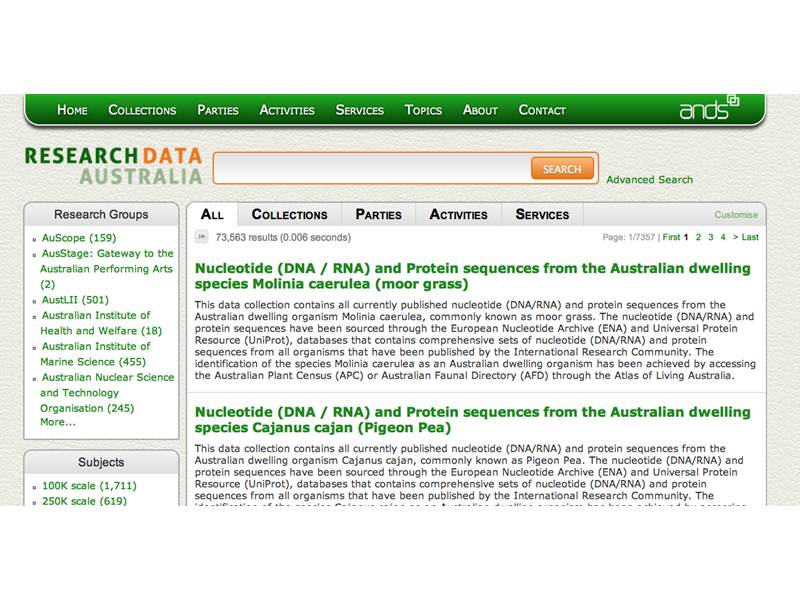
Slide 9
Research Data Australia has a gatekeeper - participating organisations submit sample records for approval before being allowed to join. The process is not perfect, but it does mean there is a chance for both local provider and global aggregator to collaborate and ANDS sponsor conversations about metadata quality.

Slide 10
ANDS is investing in projects to help work out a balance between local needs and global demands for consistency in metadata - this is a complex balancing act, ask for too much globally and you risk getting nothing. For example a project at Griffith University where Natasha Simons blogs about metadata issues. http://ands-gold-griffith.blogspot.com.au/
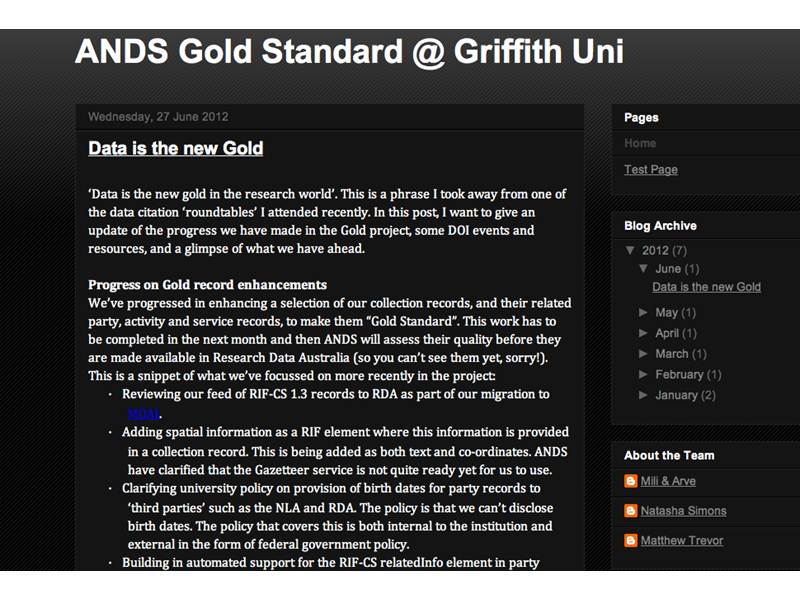
Slide 11
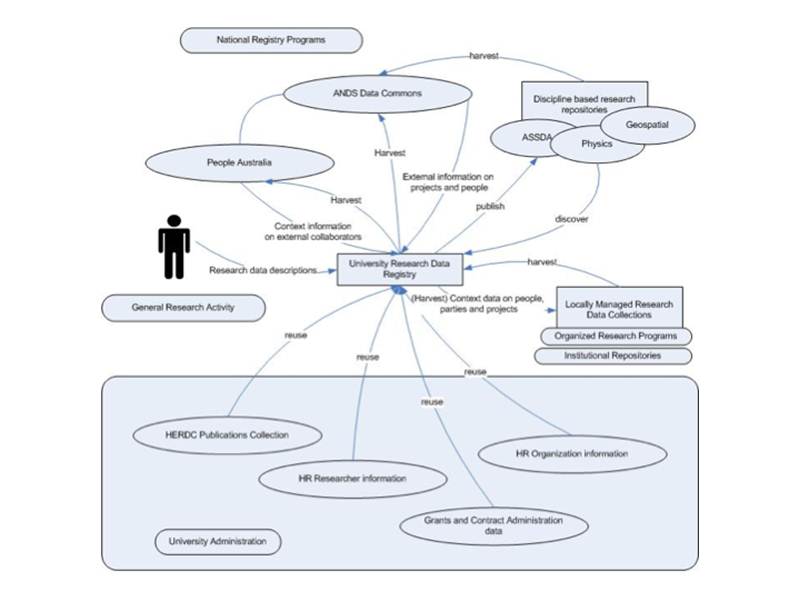
Back to architecture: the new wave of IDRs is architecturally very different from the first wave of IPRs - we have learned to collaborate better within our institutions, and look very carefully at other systems for integration points. This diagram from the planning process for the ReDBOX research data repository shows significant interaction between the IDR and external systems at the university, including processes, not just software.
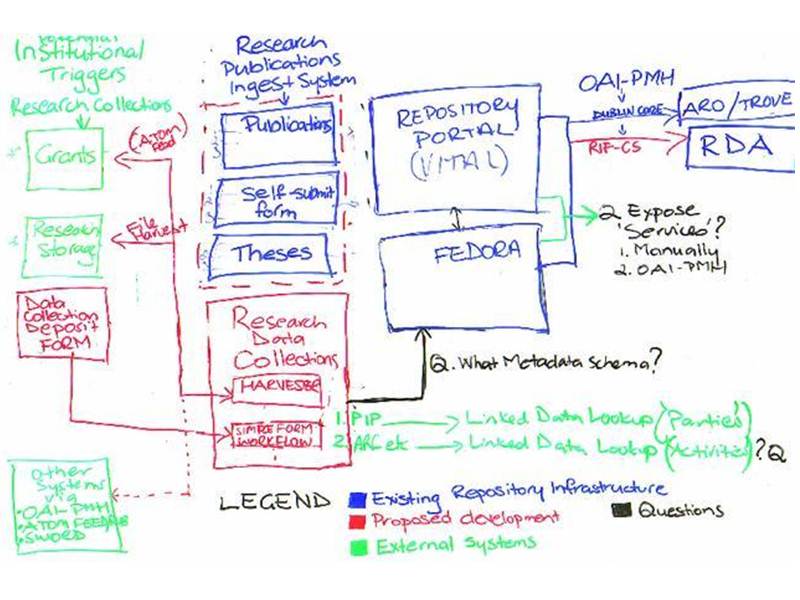
Slide 12
This is a VIVO diagram. As we have widened our focus the diagrams get more baroque - we don't recall such complex visions back in the days of the first IPRs. Also, five years ago advice for repository managers did not typically include having the chair of a repository steering group being a Deputy or Pro-Vice Chancellor for research.
Slide 13
Another trend we are seeing is the use or URLs as names for things. Both of the IDR applications we're discussing here today use a linked-data approach - VIVO is aggressively linked-data because it is a semantic web application built on RDF. ReDBOX is linked-data ready with more of a philosophy of "We'll add an RDF triple store when the first real user turns up and asks for a SPARQL endpoint"

Slide 14
Each of the repository solutions we're talking about here has a registry or catalogue component which can be used to create different views of the research life cycle for administrators, researchers, higher-degree students and so. (c) Adam Hart-Davis used with permission

Slide 15
One of the other major trends we're seeing with data repositories is automated deposit via "Data Capture" applications. Architectures vary much more widely than in the IPR days, as the community find a balance between mechanised harvesting and hand-crafting collections.

Slide 16
The data deluge is being channeled by using existing metadata and processes to contain it - we have lots of research-process information about grants, publications, people, groups, and can use this to classify data as it rains down on us.

Slide 17
In addition to the aforementioned industrial harvesting of data and automated metadata creation using contextual research information systems, there is still a role for hand-crafted rich descriptive metadata.

Slide 18
The semantic web approach of VIVO is allowing us to describe resources ever more deeply, from metadata about scholarship to the actual resources and products of scholarship using systems like eagle-I https://www.eagle-i.net/.
Slide 19
Where to from here? More slow progress, more evolving along with libraries and the scholarly process.

Slide 20
The future! May not be as neat as we'd planned, but likely to be more connected. The new-wave of repository systems should be much better networked than the first round of Institutional Publications Repositories in the early to mid 2000s. We hope this means that IDRs can play a lead role in the new networked scholarship that Cameron Neylon talked about in his keynote at Open Repositories 2012 http://www.youtube.com/watch?v=Axr80qm6NHw&feature=youtu.be
