An Australian Research Data Repository
2012-02-14
About this post
During 2012 The University of Western Sydney (UWS) will be rolling out a Research Data Repository (RDR). Peter Bugeia from Intersect put together the project proposal which secured the budget to move ahead with this project and Andrew (Alf) Leahy has been organising storage for research groups on request, ahead of the RDR becoming properly operationalised.
Part of this RDR project will be a project funded by the Australian National Data Service (ANDS) under the Metadata Stores programme. There will be a number of meetings over the next couple of months where Australian Universities discuss how they are going to spend their Metadata Stores money. There is a great opportunity for organisations running similar software architectures and solutions to pool their development resources; we’ve already spoken with Newcastle about this. We hope this preliminary material will help others in the community work out how much we have in common or tell us where we might be able to improve things. More on that at the end of the post.
Before we go on, about that term ‘Metadata Stores’
In ANDS speak, a Metadata Store is something that has all the metadata about research data and associated entities like parties (people, organisations) and activities (grant funded projects for example), in order that collection descriptions (of research data) can be published to their search service Research Data Australia (RDA).
But in many organisations we’re lacking the most important thing. We don’t have the descriptions of research data to suck up into a ‘metadata store’. Yes, there are data capture projects, lots of them which will attempt to automate to some extent the packaging process, but there’s a lot of stuff out there that won’t get captured this way. And even with automated data capture, someone still has to write the human readable description as a framework for the automated part. Many of us are getting librarians involved in this enterprise Why? They’re good at it. From a library point of view, this is a growth area, in a time when many other functions of the library are changing and/or disappearing.
Describing collections is a key part of this whole ANDS agenda, which strangely sometimes gets a bit forgotten. For example, in this diagram from the ANDS website, “collection descriptions” appear only outside of the institution. When working on these projects it’s important to keep thinking about where these descriptions are going to come from.
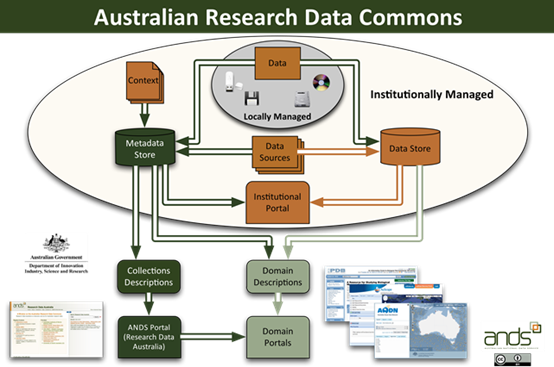
ANDS diagram showing Collection Descriptions in the Research Data Commons. But think: who's going to provide the descriptions in the institution – they’re not going to manifest spontaneously as they appear to here!
The RDR
The repository will consist of two main components:
-
A scalable storage service linked to a combination of local and cloud-based high performance computing. Some data may also reside in other, trusted storage systems such as national infrastructure or discipline repositories with suitable governance in place.
-
A catalogue of research data for internal use in management, and external use in dissemination and collaboration.
Unlike a typical monolithic Institutional Repository (IR) the storage and catalogue services are disaggregated, because the data involved can be large and is much more varied in nature than the typical contents of an IR. Also, some data will reside in trusted data stores outside of the central storage supplied by IT. Not to mention that some of it is on paper and some on obsolete digital media.
But the project is about much more than supplying storage and computing. It is about creating an organisational capability and culture of managing research data throughout the research lifecycle. We aim:
To enable research in all disciplines at UWS to take place efficiently and effectively on existing and new data sets.
To enable the validation of research through appropriate management of data inputs and outputs.
For re-use in new research which will cite the creators of data sets at UWS.
For compliance with funder requirements and codes of practice.
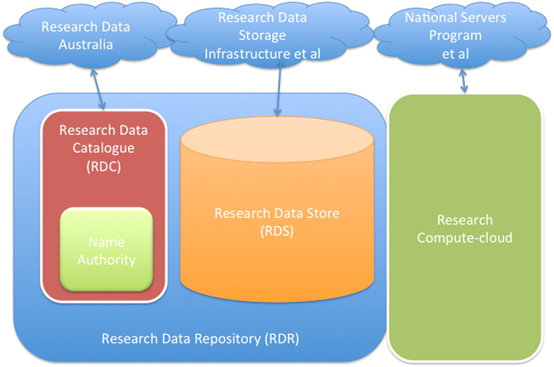
The RDR will be a locally governed service linked to national infrastructure for dissemination of research data, data storage and computing
The repository software stack will consist of:
-
Scalable, managed file storage for both working and archived data, including any discipline-specific metadata describing that data
-
Access to virtualized and non-virtualized computing infrastructure at UWS, national and commercial facilities so that researchers can run data analysis tasks.
-
A research data catalogue containing metadata about data at a collection level for code-compliance, strategic research management and discovery purposes.
-
Interfaces to national research infrastructure including storage and computing (RDSI, NCI, NeCTARetc).
The initial storage component of the RDR was established in 2010. The next steps in the RDR project are to design the architecture that links the storage to computing infrastructure and cataloguing applications, and buy a lot more discs. This architectural work will be undertaken by the eResearch Unit (That’s Peter Sefton, Andrew Leahy and our Intersect eResearch Analyst Peter Bugeia),Information Technology Services, and the University Library.
The RDR will serve several communities:
Community RDR services
Researchers - A safe place to put working data.
- A platform for collaboration around data.
- Archival storage, to meet researcher and departmental obligations to preserve data.
- A platform for describing and advertising data sets for discovery and re-use.
- A platform for publishing open access data
- A platform for protecting confidential or trade-secret data, managing embargoes and disposal dates.
- Direct connection to scalable computing resources.
- Minimal extra work for researchers over current interactions with ORS (grant applications, reporting etc).
Office of Research Services - An institutional view of where data resides.
- Integration with the research lifecycle and existing ORS systems
- Improved visibility for UWS research
The Library - Curation tools for research-services librarians to describe data sets
- Descriptions of data collections become part of the library’s holdings.
Information Technology Services - Consolidation of research data into one service model (currently storage provisioning is distributed and ad hoc).
UWS eResearch team - University processes around the RDR will make it easier to identify where eResearch needs are at UWS.
- Basic data storage is a ‘gateway’servicefor researchers into embracing more advanced computing and data-driven research (ieeResearch).
General community - The public will have an improved view of what research is conducted at UWS.
- Potential future Australian Government or other reporting on data re-use and citation rates.
External researchers - Discoverable data, people and projects
- Immediate re-use of open-access data where possible
- Mediated use data where possible, in collaborative projects or by arrangement with data creators
Fitting in to UWS
The RDR will be integrated with processes for managing the research lifecycle. It is a design goal that all researcher interaction with the system will have as little impact on the researchers as possible, by aligning form-filling and bureaucracy with existing and/or inevitable processes such as grant application or government reporting.
- Storage allocation will be tied to stages in the research lifecycle where researchers already interact with the Office of Research Services, such as grant application time. Thus all funded research projects will have appropriate working and archive storage allocated from the project start.
More about the repository software architecture
A repository is not just a software application. It’s a lifestyle. It’s not just for Christmas. And if you build it they almost certainly won’t come. The main repository-like components of the RDR, the storage and catalogue, will be loosely coupled, but there will need to be overall repository governance in place to make sure that data is well looked after. (We’re setting aside discussion of the computing component for now, more on that soon.)
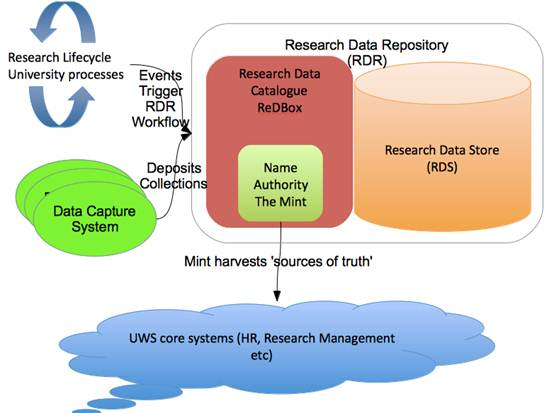
More detail about the RDR
To implement the Research Data Catalogue UWS will be using the ReDBox Research Data Catalogue application working alongside a scalable storage system (we have a post about what kind of storage and how it might be organised coming soon).
Above, we talked above about the need for systems that can describe research data collections. In most organisations we don’t know what data we have, because there is no catalogue or registry with metadata about data collections sitting there ready to be aggregated. The ReDBox application will fill this gap; it is the place where the library team will work with researchers to describe their collections, check the descriptions and finally publish them, with metadata that is as high in quality as we can manage.
Some collection descriptions will come, at least in part, from data capture software systems. It’s worth noting that many data capture projects could be a lot more ephemeral than the repository. They could be project based, or they could use software that does not have a long working life, so one of the core assumptions we’ve made is that for many data capture applications there will be a step when data crosses the curation boundary into the repository, where we know it will be looked after for the appropriate length of time. Data may or may not be moved into the storage component in the repository depending on a number of factors, including its size, the nature of the data capture application and whether it has the right governance in place to ensure that data can be managed to the standards set for the RDR. There’s a lot more to say about this interface, we’re preparing another post with a detail based on a specific implementation being built by Intersect and UWS.
Open questions for the UWS deployment include:
-
Will the catalogue itself be used for discovery or do we want to publish information about research data holdings via some other means, such as the VITAL-powered institutional repository, or via a discovery layer service?
-
Will we insist on a single RDR API to program against, or be more relaxed about how various services talk to the storage, catalogue or name authority service directly? At stake here is the integrity of the contract with researchers and the world, the contract that the catalogue matches what data we have.
Experience suggests that trying to make everything go through one tiny little software keyhole won’t work. Governance is governance, software that gets in the way gets routed-around, and it will take people to honour the various contracts involved such as the one that says once you assign a DOI (an ID, as seen in journal publishing) to a data set you don’t change the data.
Opportunities for collaboration
A number of Australian Universities have money under the ANDS Metadata Stores funding stream for projects like the UWS Research Data Catalogue. There will be lots of models for what a metadata store looks like, but if we can find some common ground then we should be able to:
-
Form a consortium of some kind, of like-minded institutions, using similar software componentry.
-
Work out which software, documentation, training course requirements are shared across sites.
-
Pool some of our funding to develop the above.
Simple, apart from the complexities of legal contracts etc. But there might be ways to divide up work, do it at different institutions and contribute it back to the commons; all ANDS-funded software deliverables are open source, and documentation etc can be made open access.
A good place to look for commonality is in the ANDS recommended deliverables.
D1 A working feed of records describing Collections and associated Activities, Parties and Services to Research Data Australia, in the current version of RIF-CS (1.3), demonstrated to meet the quality requirements for RIF-CS records as set by ANDS. D2 A feed of collections from at least three distinct Faculties (or equivalent organisational units) within the institution to Research Data Australia. D3 Demonstrated alignment of metadata records about Parties with an institutional name authority (HR or Library), with the authoritative form of the name sourced external to the metadata store, and with new researcher descriptions added to the metadata through regular updates from the name authority. D4 Demonstrated alignment of metadata records about Parties with the ARDC Party Infrastructure Project, with researcher descriptions contributed to the NLA, and with People Australia identifiers for researchers recorded against researchers. D5 Demonstrated alignment of metadata records about Activities with institutional and external sources of truth (Research Office, ARC and NHMRC grant registries), with the authoritative description of the Activity sourced external to the metadata store, and with new researcher project added to the metadata through regular updates from the sources of truth. D6 Demonstrated workflow for registering new Collections in the university; this can include automated update, or semi-automated (notification-based). D7 A software system to realise deliverables D1–D6 (and D8, D13–D14 if applicable), with robust storage and management of metadata.
To summarise, a comment about these deliverables in the light of the architecture sketched above. D6 is huge. “Demonstrated workflow for registering new Collections in the university” Most of the other deliverables are dealing with data that’s already well described, and needs to be integrated into a metadata store. One could argue that we could quite easily link a collection to a URL about a grant funded project (there’s your activities taken care of), forget about describing people at the national library or trying to set up yet another local ID, and put resources into getting ORCID up and running. But what about the all-important collections? Isn’t that the whole point? Note to other Metadata Stores project people: don’t forget, the workflow for ‘registering’ collections presupposes that you have a way of describing the collections in the first place, and making sure you can manage those collection descriptions even if some of the more ephemeral data sources (such as data capture projects) disappear.
Copyright Peter Sefton and Peter Bugeia, 2012-02-14. Licensed under Creative Commons Attribution-Share Alike 2.5 Australia. <http://creativecommons.org/licenses/by-sa/2.5/au/>