More progress on exploded PowerPoints in a desktop repository
2009-08-17
Back in June I engaged in a bit of back and forth with Les Carr about breaking up presentation files such as PowerPoints into component parts, for ingest into a repository, and about the concept of 'desktop repositories' I reported some progress with a ppt 'exploder' for ICE and talked about future plans.
The team here has made some progress in their work on The Fascinator Desktop which can blow up presentations into component parts. We're going to release a developer version very soon that you will be able to check out using Subversion (on Linux you can install it from the Trunk if you're really keen), but I will just talk about the presentation handling and some of the possibilities for that here.
What we have now is a system that ordinary users will eventually be able to install on their computer to index their local files. The idea is as I described it in the post Desktop eResearch Revolution. It will help you to discover all your digital stuff, see it and organize it in a web interface, route it to the data-fabric and/or publish it. We're up to the discovery bit at the moment, but building the whole picture is quite a major project.
-
Linda Octalina wrote a file-system watching service, which other software can access over a web-service to see what has changed (the web-bit can be optimized out if needed later).
-
Oliver Lucido rewrote The Fascinator so that a it uses Jython for a lot of the display logic, to make it easier to adapt, and replaced Fedora with a simple file based storage layer (Fedora will be an option, but is probably overkill for working files on a desktop/laptop/netbook). Ron Ward is working on a storage layer using Couch DB, to see how that might work with replication.
-
Duncan Dickinson has been managing the product and the release process, and a new site being put together by Bron Chandler. The whole thing is coming together into a project framework that we hope will be a useful contribution to the Australian National Data Service (ANDS) agenda.
-
Most importantly, Linda and Bron came up with a tag: tf4desktop.
At the moment, in the upcoming developer release you can:
-
On Linux, start up the file watcher and the little JSON-speaking web service that goes with it.
-
Start up Solr and The Fascinator.
-
Run a harvest script that pulls in whatever files you are watching, or just peruse the file system, or harvest from a repository using OAI-PMH. Want your IR on your desktop? Now you can. (In the next release with harvester will be built-in and it will poll whatever it is harvesting periodically but for now you run it manually.) This script:
-
Extracts full text and metadata from a variety of files using Aperture.
-
Feeds likely looking files to an ICE service for rendering into web-ready formats, this includes office documents in HTML but also text to speech and video conversions.
-
-
Look in your web browser talking to a local tf4desktop portal to see what you have!
I did a harvest of my messy home directory. (I let it be messy because everything in there is just working copies of stuff that is safely looked after elsewhere, I can lose it without losing more than a day or so's work.)
Here's a screenshot when I search for 'Les Carr' on my computer. Remember this is a very early preview release, but it is finding metadata. It's found a few things including this very document.
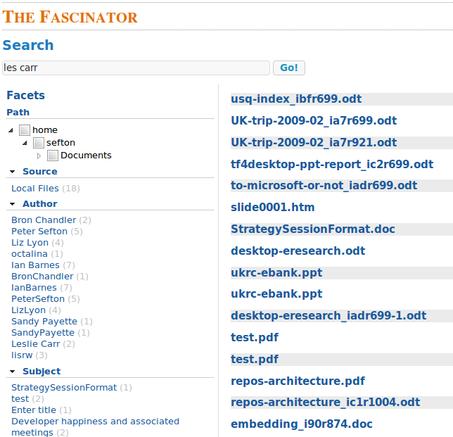
It's found a PowerPoint. If I click on the link (yes the link should use the document title), I get a lot of detail about the file.
Detail
rdf (application/octet-stream)
dc.xml (text/xml)
ukrc-ebank.htm (text/html)
ukrc-ebank.ppt.properties (text/plain)
dc-rdf (text/xml)
SOF-META (application/octet-stream)
ukrc-ebank.slide.htm (text/html)
ukrc-ebank.pdf (application/pdf)
ukrc-ebank.ppt (application/mspowerpoint)
ukrc-ebank.ppt
ukrc-ebank
There's a link to view the ICE-generated exploded and reconstituted as an HTML view:

And there's lots of metadata. For example here's a bit of RDF extracted by Aperture:
<j.0:contentLastModified rdf:datatype="http://www.w3.org/2001/XMLSchema#dateTime">2004-10-14T22:56:12</j.0:contentLastModified>
<j.0:contentCreated rdf:datatype="http://www.w3.org/2001/XMLSchema#dateTime">2002-04-27T05:42:16</j.0:contentCreated>
<j.1:contributor rdf:resource="urn:uuid:49cfc7d1-b645-4264-a240-950848cc8f9d"/>
<j.1:creator rdf:resource="urn:uuid:261f6215-4cdf-4781-9409-dd9e2b3111dd"/>
<j.0:title>eBank UK - linking research data, scholarly communications and learning</j.0:title>
</rdf:Description>
<rdf:Description rdf:about="urn:uuid:261f6215-4cdf-4781-9409-dd9e2b3111dd">
<j.1:fullname>Liz Lyon</j.1:fullname>
<rdf:type rdf:resource="http://www.semanticdesktop.org/ontologies/2007/03/22/nco#Contact"/>
</rdf:Description>
<rdf:Description rdf:about="urn:uuid:49cfc7d1-b645-4264-a240-950848cc8f9d">
<j.1:fullname>Leslie Carr</j.1:fullname>
<rdf:type rdf:resource="http://www.semanticdesktop.org/ontologies/2007/03/22/nco#Contact"/>
</rdf:Description>
This is the first time we've had all these pieces put together and at the moment, they can be used to index and search a bunch of files; it's useful already, partly in that it shows me that in a lot of cases the metadata in my documents is, well, sub-optimal. The reason it shows me I have ten documents by Pamela Glossop or 53 By Ian Barnes is not because I do, it's because a couple of the templates I use a lot were made by those two people, and I have not been setting the metadata in the document properties.
I have just looked at presentations here, but part of the point of The Fascinator is that it is extensible to deal with any kind of file – it will come with default handler for audio and video and images and be able to find embedded data like geographical points, but you will also be able to plug in handlers for other formats, such as chemistry, or climate data.
I'll finish up with a few notes on things we need to do, to feed into the requirements for 0.2 and beyond:
-
Implement the hierarchical search features I mentioned in a previous post where you would be able to show a hit for 'dog' in one slide and 'cat' in another but see that they come from the same presentation.
-
Work out ways to reassemble slides (or pictures, or saved web pages, any item really, into web presentations using something like the 'organizer' we have in ICE, and then expose these as OAI-ORE resource maps.
-
Turn the above (if they consist of slides) into a new presentation by extracting and reassembling the original source slides in their native format.
-
Be able to push exploded PowerPoints (or plain old documents) to a blog via Atompub, or to a repository via SWORD. We already have the technology in ICE, via the ICE-Theorem project – bring on the one-click deposit! Even better, do auto deposit based on some criteria like stuff I have tagged as 'published'.
-
Allow for batch fixing-up of metdata, like removing Ian Barnes as creator of stuff he didn't create.
-
Work out how we are going to work with backup system and file replication schemes.
-
Look at closer integration with ICE for things like courseware or theses.