DataCrate: a method of packaging, distributing, displaying and archiving Research Objects
2018-10-29
Here are the slides for presentation I delivered this week at Research Object 2018 in Amsterdam. The paper we wrote for this workshop is available. The contributors to the article are:
- Peter Sefton
- Michael Lynch
- Gerard Devine
- Duncan Loxton
- Sharyn Wise
- Christian Evenhuis
This presentation is my view on some the issues in data packaging and linked data metadata. In addition to giving a quick intro to DataCrate I tried to contrast it with the Research Object and Frictionless Data approaches and to talk about some of the issues we had with software tooling for linked data in JSON-LD.

Notes - Slide 1
DataCrate is a specification for packaging research data for distribution and reuse. DataCrate packages may be distributed as archives with or without compression, and hosted on web sites, as they contain an index.html page that summarizes the contents of the package for human readers. For machines, there is a JSON-LD file containing metadata that will aid in the re-use of the data including licensing, publication dates, parties involved in creating the data. Where possible the terms from schema.org are used for metadata, with other ontologies used where needed. DataCrate optionally uses the BagIt data packaging standard which is widely used in libraries and archives and increasingly in research data management, including in recent discussions about data packaging at the Research Data Alliance (RDA).

Notes - Slide 2
Hi, I’m Peter, you can call me Petey.
I’ve made a solemn vow never to invent an ontology.
Also, I seem to have become the main contributor to a new standard. This was NOT one of my ambitions as a kid, frankly I’d like to spend my spare time playing or writing music rather than maintaining standards.

Notes - Slide 3
We wanted to be able to show data on the web and distribute it with useful metadata. That means allowing a data packager to anticipate what others (including their future self) might want to do with data, and providing enough detail on data provenance to make that possible.

Notes - Slide 4

Notes - Slide 5
Here’s an example. This is the dataset used as the test-case for the first DataCrate.
This came from Cameron Neylon’s As a researcher…I’m a bit bloody fed up with Data Management, which I covered in the First presentation about DataCrate

Notes - Slide 6
DataCrate uses several standards:
🛄it - BagIT
⛓💾 - Linked data as JSON-LD
<html></html> - HTML
And the Schema.org vocabulary.
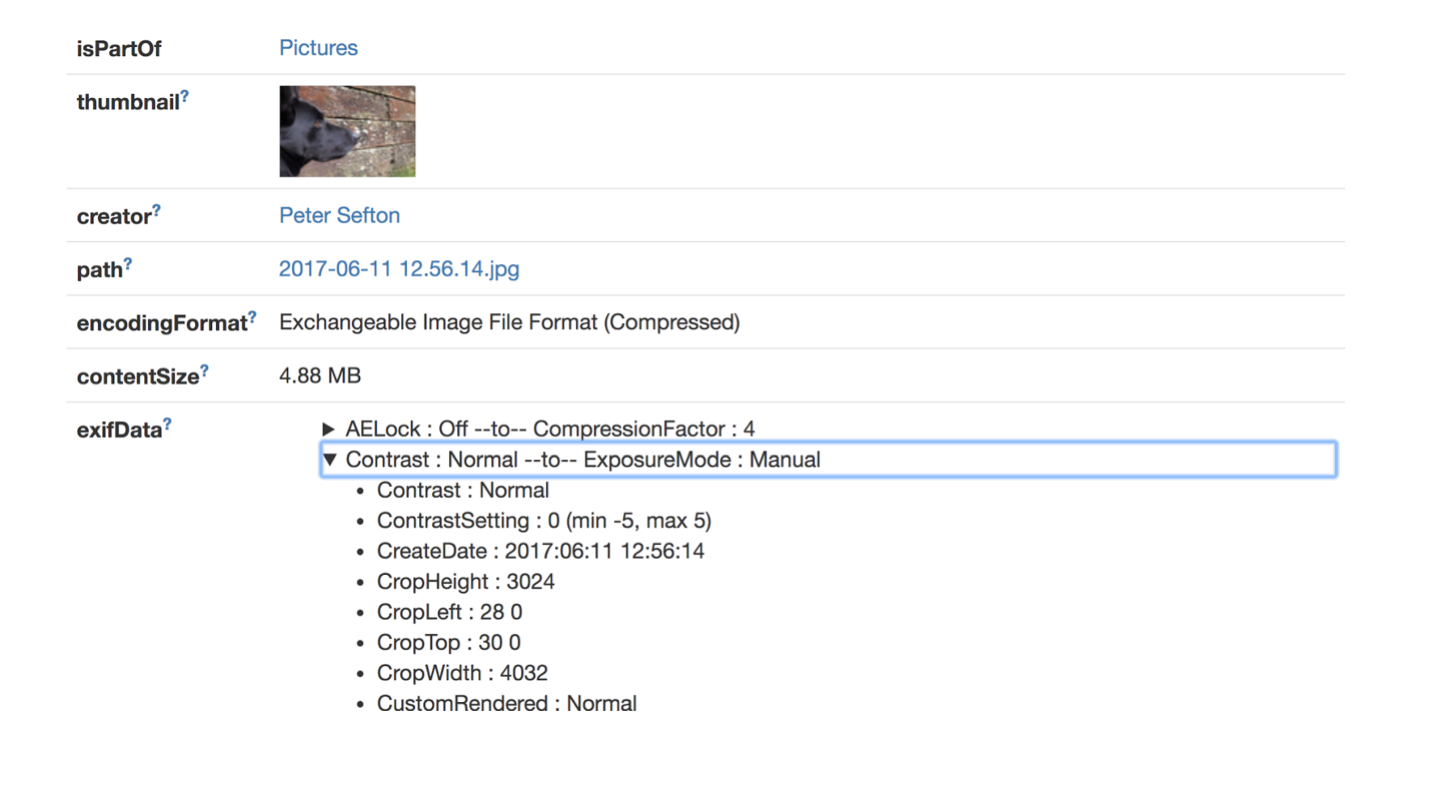
Notes - Slide 7
Human-readable HTML data about files including detailed metadata.

Notes - Slide 8
Which allows us to describe individual items of equipment ...
As Carl Kesselman said at the workshop:
Why isn't FAIR important when you take it off the microscope?
Chris Evenhuis at UTS thinks the same way. He is doing stuff because it is the right thing to do.

Notes - Slide 9
… people ...
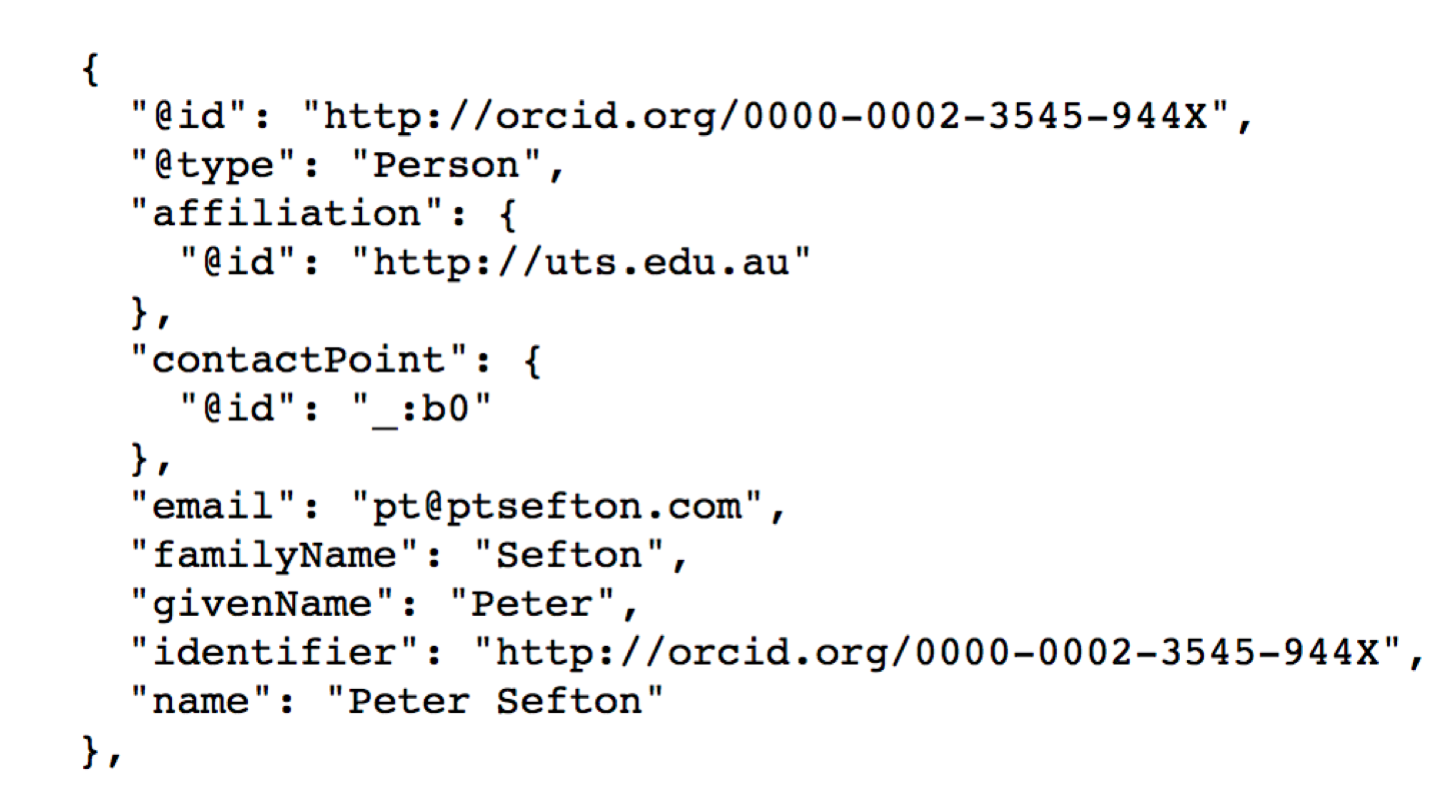
Notes - Slide 10
All the metadata for a Datacrate is in a single JSON-LD file. This is easy for programmers to deal with, and in my opinion, much more straightforward than the Research Object approach of using multiple annotation files - this has nothing to do with differences in the information model, its an implementation detail.

Notes - Slide 11
Processes by which files are created

Notes - Slide 12
Because DataCrate is based on JSON-LD, and linked data pricnples, each term used can have a link to its definition, eg: https://schema.org/CreateAction
ing is limited:
JSON-LD → 🙅
⛓💾 → 👶</p>
<p>")
Notes - Slide 13
Tools (🔧🔨🔩🔪🔬) for humans to generate linked-data are under-developed.
JSON-LD tooling is limited to high-level transformations and there are no easily available libraries for Research Software Engineers to do simple stuff like traversing graphs or looking up context keys.
Linked Data data tooling is also extremely lacking, there are very few good example of systems that allow people to enter linked-data metadata.

Notes - Slide 14
Linked data is still too much like rocket science (🚀⚗️) because of all the architecture (👩🏽🚀👷🏗️🏢) astronauts.
These are the people I call Architecture Astronauts. It’s very hard to get them to write code or design programs, because they won’t stop thinking about Architecture. They’re astronauts because they are above the oxygen level, I don’t know how they’re breathing. They tend to work for really big companies that can afford to have lots of unproductive people with really advanced degrees that don’t contribute to the bottom line.
There’s also religious aspect to some of this.

Notes - Slide 15
We need to stop treating ontologies like toothbrushes (ie avoiding using other people’s) and get on with implementing usable systems.

Notes - Slide 16
So I’ll finish with a provocation.
Do we really really need more complicated ontologies when you can describe the what where when and why of research data in a useful way with schema.org and JSON-LD? We need to recruit content and get experience describing it, not wait.