DataCrate Formalising ways of packaging research data for re-use and dissemination
2017-10-19
[Update: 2017-10-20 Fixed a few typos and some formatting.]
This is a presentation I gave at eResearch Australasia 2017-10-18 about the new Draft (v0.1) Data Crate Specification for data packaging I've just completed, with lots of help from others (credits at the end).
BACKGROUND
In 2013 Peter Sefton and Peter Bugeia presented at eResearch Australasia on a format for packaging research data(1), using standards based metadata, with one innovative feature – instead of including metadata in a machine readable format only, each data package came with an HTML file that contained both human and machine readable metadata, via RDFa, which allows semantic assertions to be embedded in a web page.
Variations of this technique have been included in various software products over the last few years, but the there was no agreed standard on which vocabularies to use for metadata, or specification of how the files fitted together.
THE PRESENTATION
This presentation will describe work in progress on the DataCrate specification(2), illustrated with examples, including a tool to create DataCrate. We will also discuss other work in this area, including Research Object Bundles (3) and DataConservency(4) packaging.
We will be seeking feedback from the community on this work should it continue? Is it useful? Who can help out? The DataCrate spec:
-
Has both human and machine readable metadata at a package (data set/collection) level as well as at a file level
-
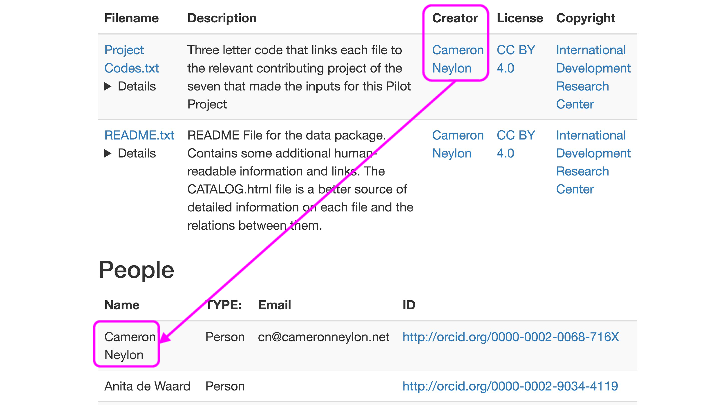
Allows for and encourages inclusion of contextual metadata such as descriptions of organisations, facilities, experiments and people linked to files with meaningful relationships (eg to say a file was created by a particular machine, as part of a particular experiment, at an organisation).
-
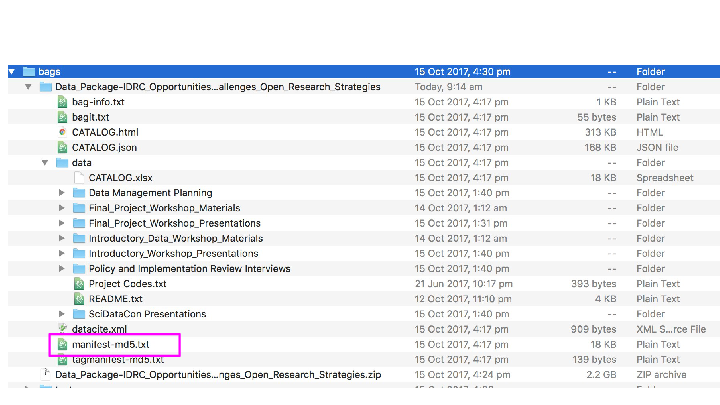
Is a BagIt profile(5). BagIt(6) is a simple packaging standard for file-based data.
-
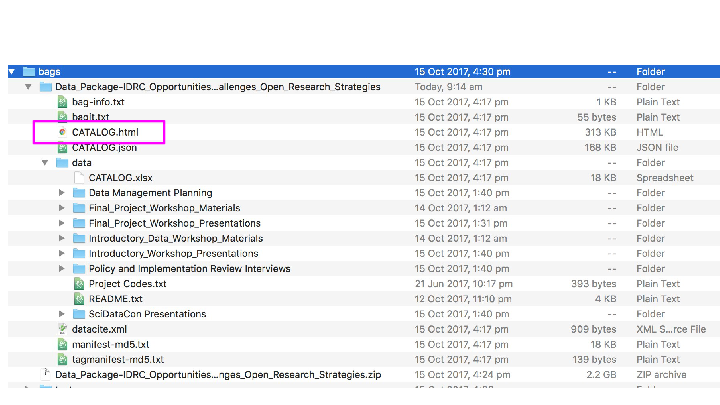
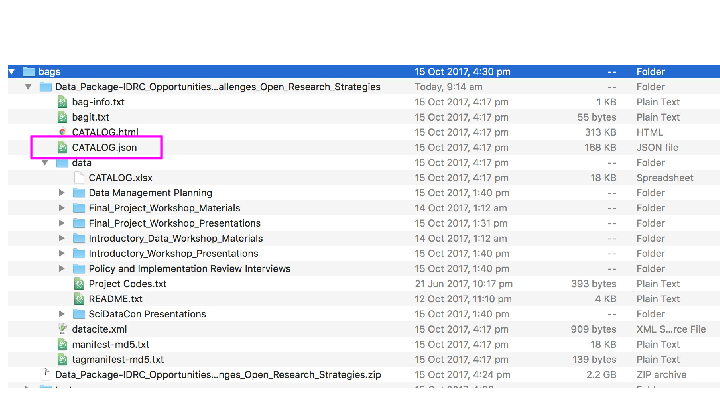
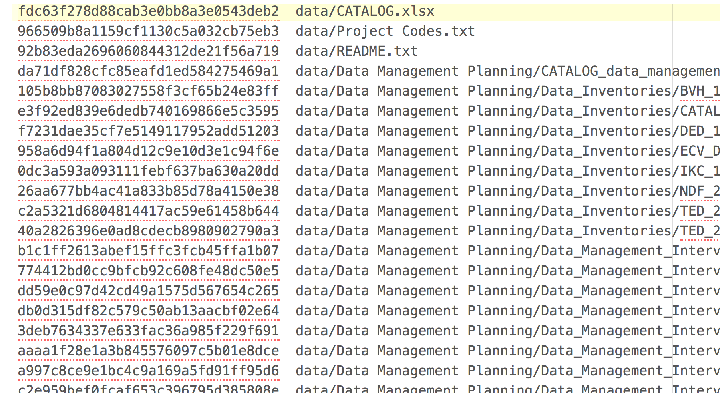
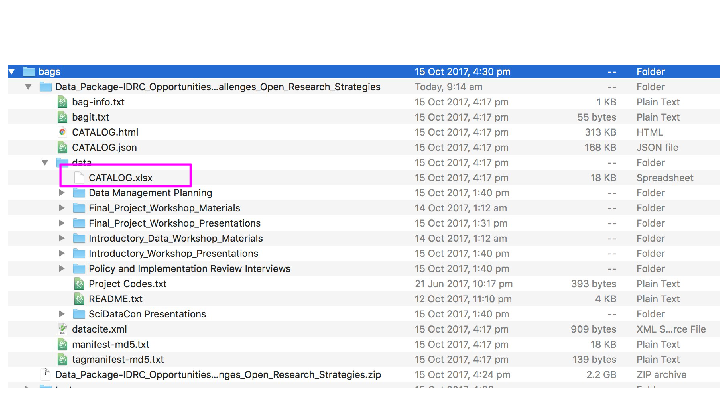
Has a README.html tag file at the root with bagit-style metadata about the distribution (contact details etc) with a link to;
-
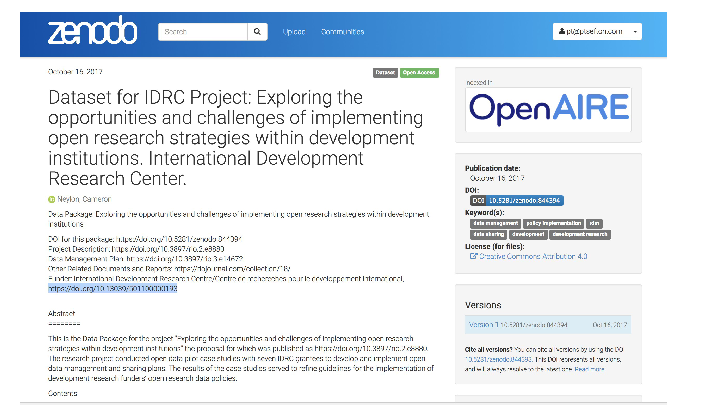
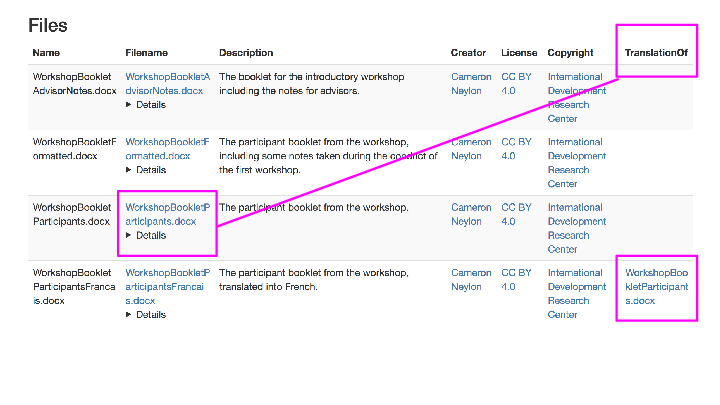
a CATALOG.html file in RDFa, using schema.org metadata inside the payload (data) dir with detailed information about the files in the package, and a redundant CATALOG.json in JSON-LD format
-
Is extensible easily as it is based on RDF.
REFERENCES
Sefton P, Bugeia P. Introducing next year’s model, the data-crate; applied standards for data-set packaging. In: eResearch Australasia 2013 [Internet]. Brisbane, Australia; 2013. Available from: http://eresearchau.files.wordpress.com/2013/08/eresau2013_submission_57.pdf
datacrate: Bagit-based data packaging specification for dissemination of research data with useful human and machine readable metadata: “Make Data Crate Again!” [Internet]. UTS-eResearch; 2017 [cited 2017 Jun 29]. Available from: https://github.com/UTS-eResearch/datacrate
Research Object Bundle [Internet]. [cited 2017 Jun 16]. Available from: https://researchobject.github.io/specifications/bundle/
Data Conservancy Packaging Specification Home [Internet]. [cited 2017 Jun 29]. Available from: http://dataconservancy.github.io/dc-packaging-spec/dc-packaging-spec-1.0.html
Ruest N. BagIt Profiles Specification [Internet]. 2017 Jun. Available from: https://github.com/ruebot/bagit-profiles
Kunze J, Boyko A, Vargas B, Madden L, Littman J. The BagIt File Packaging Format (V0.97) [Internet]. [cited 2013 Mar 1]. Available from: http://tools.ietf.org/html/draft-kunze-bagit-06

Slide notes

Slide notes
Slide notes
Back in June Cameron Neylon was [annoyed](http://cameronneylon.net/blog/as-a- researcher-im-a-bit-bloody-fed-up-with-data-management/)

Slide notes

Slide notes

Slide notes




Slide notes



Slide notes

Slide notes
Slide notes


Slide notes


Slide notes

Slide notes
Slide notes


Slide notes

Slide notes

Slide notes

Slide notes

Slide notes

Slide notes
Slide notes
Slide notes


Slide notes

Slide notes

Slide notes

Slide notes
Slide notes
Slide notes

Slide notes


Slide notes


Slide notes

Slide notes

Slide notes
-
Cr8it - now being looked after by Newcastle.edu.au (via Western Sydney and Intersect) https://github.com/digitalbridge/crateit/tree/develop
-
HIEv https://github.com/IntersectAustralia/dc21
-
Mike Lake's CAVE repository. https://suss.caves.org.au/cave/
Cr8it and HIEv are covered in our 2013 presentation at eResearch Australasia
It builds on other standards:
-
BagIt: https://tools.ietf.org/html/draft-kunze-bagit-14
-
Schema.org http://schema.org
Slide notes

Slide notes
-
Lobby to get support integrated into Zenodo, Figshare et al
-
Improve capture/packaging tools (Cra8it, Cloudstor Collections
-
Work with others on aligning this work with other standards, [here's a list someone else put together](https://docs.google.com/document/d/155lA2BcixTl- zwJHGfLkxsmg7WmQbBK00QWyP8QggkE/edit).
-
Work with RDA on their repository interchange format. https://www.rd-alliance.org/groups/research-data-repository-interoperability-wg.html

Slide notes
Thanks to:
-
Cameron Neylon for being customer zero
-
Liz Stokes for working on metadata crosswalking/mapping
-
Mike Lake for coding and ideas
-
Conal Tuohy and Duncan Loxton for commenting on the draft spec
-
Amir Aryani for discussions about metadata
And the mainly Sydney-based metadata group who met in the leadup to this work Piyachat Ratana, Sharyn Wise, Michael Lynch, Craig Hamilton, Vicki Picasso, Gerry Devine, Katrin Trewin, Ingrid Mason, Peter Bugeia