I wrote recently about a potential technique to help manage file-based research data so researchers can identify and ‘package’ collections or sets of data for deposit in a repository. This is an update on that, reporting more progress on integrating the data capture part of the chain, where a researcher can identify and package-together a set of data files, and the catalogue/repository part where librarians are involved in the process of quality-checking metadata, and publishing a record about the data, including to Research Data Australia.
My previous post showed screen shots of what the data capture app would look like. You can now play witha live demo running on the NeCTAR cloud. If you really want to play, ask me to share the Dropbox with you so you can add lots of files. It won’t be there forever and it may break log in with admin/admin and try making a ‘package’ (let me know if you can figure that out or not).
There is also a copy of the ReDBOX research data catalogue/repository running on the NecTAR cloud, and it’s watching the other demo server (answering the question, finally, of who will watch the file watcher). New packages show up in the OAI-PMH feed there and get ingested into the ‘investigation’ stage in the repository. Again, this won’t be there long term but you can have a look (log in as admin/rbadmin).

Figure 1 Packages created in a file-watching application which have been automatically fed into the first stage of a ReDBox Research Data Catalogue workflow
This activity diagram shows the flow of feral files from capture to catalogue.
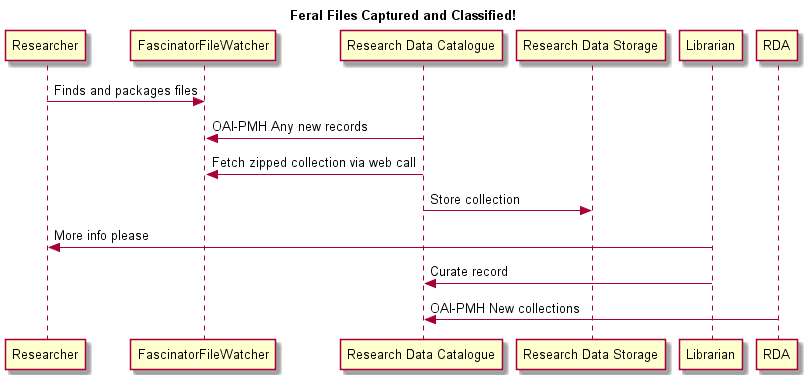
Figure 2 Activity diagram for the process of getting a collection of files from a researcher's storage area through to the catalogue and institutional store, and published to Research Data Australia (RDA)
Copyright Peter Sefton 2012. Licensed under Creative Commons Attribution-Share Alike 2.5 Australia. <http://creativecommons.org/licenses/by-sa/2.5/au/>