| au) |
| University of Southern Queensland | |
| | |
| | <span |
| | class="meta-familyname">University |
| | of Southern Queensland |
+--------------------------------------+--------------------------------------+
[Update: added link to the paper] The short paper Duncan Dickinson and
I put together for this
conference
is organised around the conference themes, and what our Research and
Development group at the Australian Digital Futures Institute is doing
about each of them. In this presentation I will pick out some of the the
work we're doing and some of the issues we're thinking about, and try to
relate this work back to the conference themes. It's gratifying to be
able to make this presentation. Some of the core ideas we're talking
about here were the subject of a proposal I submitted for Open
Repositories 2007, but it received mixed reviewer feedback and was
relegated to a poster; my message that repositories were stuck in “Web 0.5” and needed to be made more webish was
not timely.1
Conference themes
Please tick these off as I go.
The web and the repository & The cloud and the desktop*
Knowledge and technology
Wild and curated content
Linked and isolated data & Ad-hoc and long-term access
Disciplinary and institutional systems / Scholars and service
providers
Duncan:“A set of purposeful
technologies brought together by standard interfaces for data
exchange?”Peter:“I needed a single cover-all name for all
the different projects we were working on in our institute, so
that I could try to report to the powers that be in a more efficient
way.”
The Web and the Repositories
We're on the web, but are we of the web?
Show and tell
Repositories need to understand renditions and rendering
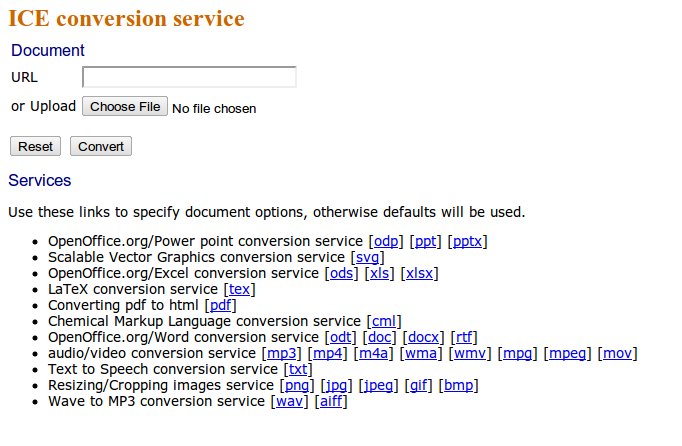
Rendering: The ICE
service– renders web versions of
everything it can and extracts metadata.
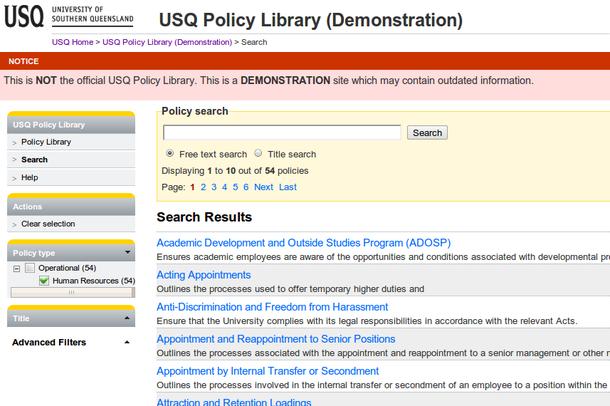
Renditions: See our site for USQ
policies.
HTML all the way.
We're working on small pieces of web-infrastructure that should
apply across multiple repositories.
Anotar: annotations toolkit designed to be easy to plug in to
any web system – even I can
do it. See this WordPress
version.
(Not as good as digress.it
but much more portable).
Paquete:
An ePUBesque reader you can embed in any web page. Also a way
for us to support compound objects in a repository.
We're working on bringing the web to the desktop. <Insert demo of
The Fascinator Desktop>
Screenshot: HTML documents derived from Word documents
Screenshot: ICE conversion service
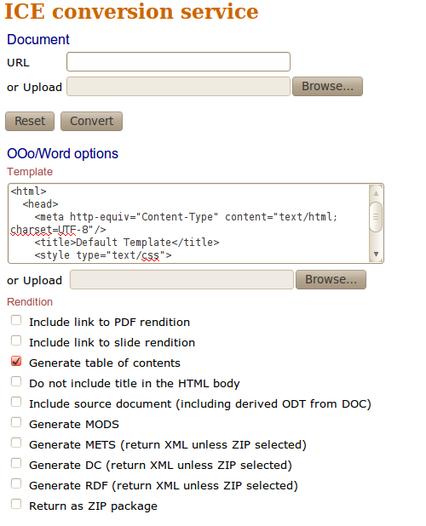
Screenshot: ICE conversion options for word processing
Screenshot: Annotations on a (this) document
Screenshot: Paquete stand-alone demo
Issue: What will happen when vertically controlled computing platforms are the norm?
Does the desktop/lab/home PC become a server? Or will it live in the
cloud?
I brought an iPad with me on this trip, but I have found that I can't
put music on it or look at the books I have bought across four– yes, four – different reader applications using
standard file-operations. Imagine the problems if we have to deal with
valuable research data which lives on these controlled devices. A whole
new era of format lock-in that makes Microsoft look like a free-software
hippy. This is one reason why the web, and delivering stuff in web
formats is important.
Idea: How about ePUB as a repository packaging format?
(In my reading of the specs) ePUB is engineered for overloading:
A zip file containing:
(At least) XHTML, with optional extra elements & a flat table of
contents.
Can include video, chemistry, whatever if you provide fallback
image/text.
Allows for alternate renditions such as PDF, docx or odt originals.
We could include an HTML 5 version (using something like Paquete)
for modern browsers/devices.
Javascript is allowed – but
must be ignored by ePUB readers but could be used by web apps.
Serve the content using an in-page eReader (Paquete).
Let the package handle package semantics (pre-print, published
version, presentation), repository can continue to handle streams.
Support viewers for data types for defined periods, such as JMOL for
chemistry using
something like ePUB's fall-back mechanism and oEmbed.
Users:
If all else fails: unzip the package and click 'index.html'
Use with eBook reader software/hardware.
Developer / repository manager:
Add more packaging info – ORE,
METS etc.
One of the other things were look at at ADFI is ways of bootstrapping
the Linked-Data/Semantic Web. I (Peter) have proposed a way of embedding
RDF statements in documents using simple interoperable URIs. Duncan has
taken this work further with a system that can serve 'proper' RDF. The
demo here shows this technique for metadata, but it could also be
applied for other kinds of semantics, when you are talking about
someone, for example rather than asserting that they are an author or an
editor.
Idea: Making linked data, well, links
Step 1: Approach your repository or ID provider, search for self
http://nla.gov.au/nla.party-541658 Note: wrapping this link around some text
is essentially meaningless. It's not the semantic web it's the
old-web.
Step 2: Copy the link labelled “Assert Authorship”http://ontologize.me/meta/?r=http://purl.org/dc/terms/creator&o=http://nla.gov.au/nla.party-541658``
Word processor-proof linked data – part 2
Step 3: Paste onto document text Author: Peter
Sefton
Step 4: Deposit somewhere that understands
<oai_dc:dc><dc:title>AWE - Presentation for Open Repositories 2010</dc:title>...<dc:creator>http://nla.gov.au/nla.party-541658</dc:creator></oai_dc:dc>
Conclusion
We (like many others) are building a toolkit for web/repository
construction. The key reasons we rolled our own are:
We care about having web-resources not just PDF.
We wanted to be able to deploy the application to the desktop (hence
a Java app that can be deployed with Apache Solr).
1 At dinner on
Monday night I was told that the ideas we're pushing here at ADFI are
“15 years ahead” of where the users are. Given that this
paper was accepted, and doing some quick maths in my head I think that
means that we have only 25 months before the things that we're talking
about here are considered relevant, given that we're working in Internet
time.